


résultats de l'appel à projets NumPEx
Le programme NumPEx lance son premier appel à projets afin de soutenir les avancées dans les domaines du calcul haute performance (HPC), de l’analyse de données haute performance (HPDA) et de l’intelligence artificielle (IA). Notre programme de recherche « France 2030 » vise à développer des logiciels capables de faire fonctionner les futures machines exascale, ainsi qu’à préparer les principaux codes d’application scientifiques et industriels.
Cet appel à projets s’articule autour de trois axes :
- Méthodes, algorithmes et logiciels d’IA émergents pour le calcul scientifique et le calcul intensif pour l’IA.
- Modèles de programmation pour architectures accélérées.
- Flux de travail pour l’analyse de données scientifiques, avec le projet SKA comme cas d’utilisation.
DAIMOS - Optimisation de l'entraînement des modèles d'IA distribués à grande échelle
Responsable du projet: Julien Herrmann, chercheur au CNRS
L’entraînement de modèles d’IA à grande échelle pose des défis majeurs, notamment en termes de coût de l’
s de calcul et d’efficacité énergétique. Ce projet s’attache à résoudre ces problèmes en développant une nouvelle pile logicielle
dédiée à l’apprentissage profond à grande échelle, fondée sur une intégration étroite des avancées algorithmiques, de l’optimisation de l’
au niveau des systèmes et de cas d’utilisation concrets. Il s’inscrit directement dans les priorités du programme PEPR NumPEx
consacré au calcul haute performance (HPC) pour l’IA.
SAGe-HPC - Stratégies intelligentes pour l'optimisation multi-fidélité dans les environnements de calcul haute performance (HPC) à l'exascale
Responsable du projet : Laëtitia Giraldi, chercheuse à l’Inria
Le projet SAGE-HPC vise à développer une plateforme logicielle évolutive, ouverte et interopérable destinée à l’optimisation par «
» à plusieurs niveaux de fidélité de problèmes physiques complexes dans des environnements de calcul haute performance (HPC) à l’exascale.
La résolution de ces problèmes d’optimisation constitue un défi scientifique majeur en raison de la complexité
des phénomènes physiques en jeu et du coût de calcul associé aux simulations à haute fidélité.
Pour relever ce défi, le projet s’appuie à la fois sur l’utilisation coordonnée de modèles à fidélité variable —
où des modèles simplifiés et peu coûteux guident l’exploration de l’espace des solutions, tandis que des modèles haute fidélité sont
utilisés de manière sélective pour affiner les résultats — et sur l’exploitation massive de ressources HPC exascale, permettant
un traitement parallèle à grande échelle de ces approches.
KOKTAILS - Kokkos : la traduction et l'interopérabilité au service des logiciels
Responsable du projet : Stéphane de Chaisemartin, ingénieur à l’IFPEN
Le projet KOKTAILS vise à améliorer la portabilité des logiciels de simulation sur les architectures d’
s de calcul exascale, en contribuant au développement d’une pile logicielle souveraine adaptée aux supercalculateurs basés sur des GPU de type «
». Il s’inscrit dans la stratégie NumPEx du PEPR et contribue à la souveraineté numérique de l’
e française dans le domaine du calcul haute performance (HPC). Il comprend le développement d’un middleware évolutif
afin de garantir la portabilité des performances sur diverses architectures GPU, y compris les processeurs européens
tels que SiPearl Rhea. Le projet contribue ainsi à la transition des applications existantes
vers le calcul exascale, grâce à la création d’un écosystème open source conforme à la politique européenne de souveraineté
.
ASTRA - Tâches avancées FR-SRC et allocation des ressources
Responsable du projet : Marc-Antoine Miville-Deschênes, chercheur au CNRS
Ce projet de recherche porte sur la transformation majeure en cours dans le domaine de la radioastronomie, portée par des observatoires de nouvelle génération tels que LOFAR 2.0 et le SKA. Ces instruments génèrent des ensembles de données volumineux et hétérogènes, répartis sur plusieurs sites, qui ne peuvent être traités efficacement à l’aide des méthodes traditionnelles de traitement des données. Le projet vise à surmonter ces goulots d’étranglement structurels en développant une plateforme numérique unifiée et évolutive qui fédère les ressources de calcul haute performance (HPC), de cloud et de stockage d’objets. Elle permettra l’exécution de flux de travail complexes (y compris le traitement basé sur l’IA) sur des infrastructures hétérogènes grâce à des technologies modernes de conteneurisation. Des principes clés tels que la provenance des données, la reproductibilité et le calcul économe en énergie seront intégrés afin de prendre en charge à la fois les flux de travail scientifiques interactifs et automatisés.
Trans Numériques 2026
Le PEPR NumPEx était fier de participer à la première édition des Trans Numériques ! Treize PEPR se sont réunis du 2 au 5 février au Couvent des Jacobins à Rennes pour partager les avancées scientifiques et les défis liés à la performance, la sécurité, la frugalité et l’impact sociétal du continuum numérique.
Cet événement a été l’occasion pour NumPEx de se réunir pour réfléchir aux prochaines étapes du programme, en particulier sur trois thèmes majeurs : La convergence IA et HPC, l’écosystème logiciel et le continuum numérique. En même temps, cet événement a permis d’échanger des idées avec d’autres PEPR et de partager des projets inter-PEPR avec la communauté numérique.
Enfin, nous sommes très fiers de Méline Trochon et Théo Jolivel, doctorants au NumPEx, qui ont représenté le NumPEx dans la vidéo de l’ANR et ont partagé leur regard neuf sur l’événement !
Programme NumPEx
Mardi 3 février 2026
- Introduction aux sessions NumPEx uniquement
- Convergence IA et HPC
- Ecosystème logiciel
- Continuum numérique
Mercredi 4 février 2026
- Convergence IA et HPC – atelier
- Ecosystème logiciel – atelier
- Continuum numérique – atelier
Jeudi 5 février 2026
- Restitution de l’atelier
Thomas Crabot
Le film ANR de l'événement

La première assemblée générale de YoungPEx
Le comité YoungPEx est une initiative de NumPEx visant à rassembler de jeunes chercheurs pour discuter de l’avenir du calcul à haute performance et de la science ouverte. Cet événement a été une première étape importante pour dynamiser le comité et parler de sujets qui seront essentiels à l’avenir. Plusieurs ateliers ont été organisés :
- Un atelier sur l’impact environnemental du HPC
animé par Georges Da Costa, professeur à l’Université de Toulouse et membre d’Exa-SoFt - Une assemblée générale pour discuter des actions à venir du comité YoungPEx et du renouvellement des membres organisateurs.
- Un atelier sur le thème des inégalités sociales et de genre
Mercredi 12 novembre 2025
Cette première journée d’atelier a été animée par Georges Da Costa, professeur à l’Université de Toulouse et membre d’Exa-SoFt.
- L’informatique durable ?
- Avenir du calcul haute performance : prochaines étapes pour le calcul haute performance ?
- Introduction à la grille 5000
Jeudi 13 novembre 2025
Cette deuxième journée a été l’occasion d’approfondir les thèmes de la première journée.
L’après-midi a été consacrée à rassembler les membres de la communauté, à échanger sur leurs travaux par le biais de nombreuses activités :
- Antithèse: Quatre présentations ont été préparées avant la journée, et quatre participants se sont portés volontaires pour la présenter, en découvrant les diapositives 5 minutes avant la présentation.
- Start-up nation : les participants ont été divisés en quatre groupes et ont dû créer une présentation d’une start-up ou d’un projet de recherche qui susciterait l’intérêt de tous les membres.
- Retour d’information sur l’atelier et émergence d’idées
- Idées pour les actions futures de YoungPEx.
Vendredi 14 novembre 2025
Le dernier jour, le thème principal était l’équité et l’égalité dans les sciences. Trois sessions différentes ont été organisées :
- le Monopoly des inégalités, un jeu inspiré du célèbre Monopoly, destiné à mettre en évidence le fait que tout le monde n’a pas les mêmes chances de réussir, animé par Yasmina Asso de l’Observatoire des inégalités;
- Présentation par Julie Lesthelle, de l’Université de Bordeaux, des résultats de son mémoire de master intitulé Les études en licence de mathématiques sous le prisme du genre : Construction d’un environnement masculin et expériences des étudiantes en situation minoritaire.
- Une table ronde sur le concept de leaking pipeline, avec l’intervention d’Elsa Cazelles (Chargée de Recherche à l’IRIT), Sylvie Chambon (Professeure des Universités à ENSEEIHT), Julie Lesthelle (étudiante à l’Université de Bordeaux), Lucie Baudouin (Directrice de Recherche au LASS) et Aline Roc (ingénieure de recherche au CATIE).
Ces sessions ont permis de faire le point sur la question de l’égalité et de l’équité et de formuler des recommandations et des signaux d’alerte pour identifier ou prévenir d’autres inégalités au sein de la communauté NumPEx.
Comité d'organisation
- Thomas Saigre, postdoctorant Inria à l’IRMA et membre d’Exa-MA
- Karmijn Hoogveld, doctorant CNRS à l’IRIT et membre d’Exa-SofT
- Méline Trochon, doctorante Inria au LaBRI et à Exa-DoST
- Mathis Certenais, doctorant de l’Université de Rennes à l’Irisa et membre d’Exa-AtoW
- Romain Garbage, ingénieur Inria et membre d’Exa-DI
Les organisateurs tiennent à remercier tous les participants à cet événement, ainsi que Georges Da Costa, Yasmina Asso, Julie Lesthelle, Elsa Cazelles, Sylvie Chambon, Lucie Beaudouin et Aline Roc pour leur temps et leur participation aux différentes activités !



Karmijn Hoogveld, Alfredo Buttari
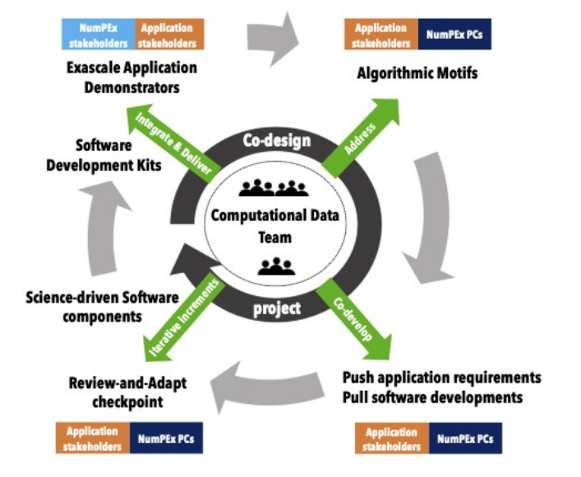
Exa-DI : la première mini-application issue du co-développement est désormais disponible !
Suite aux réunions générales d’Exa-DI, des groupes de travail ont été constitués pour produire des applications sur quatre thèmes majeurs. La première mini-application sur la discrétisation de haute précision est maintenant disponible.
Suite aux ateliers Exa-DI, quatre groupes de travail (GT) ont été constitués, réunissant tous les acteurs impliqués dans la co-conception et le co-développement : l’équipe Computational and Data Science (CDT) d’Exa-DI, les membres des différents projets NumPEx ciblés et les équipes de démonstration d’applications. Ces groupes se concentrent sur la discrétisation efficace, les maillages non structurés, l’AMR structurée par blocs et l’IA appliquée aux problèmes inverses linéaires à l’échelle exascale.
Grâce à ces groupes de travail, les premières mini-applications partagées, représentatives des défis techniques des applications exascales, sont en cours de développement. Elles intègrent des composants logiciels à forte valeur ajoutée (bibliothèques, frameworks, outils) fournis par d’autres équipes NumPEx. Dans ce contexte, la première mini-application sur la discrétisation de haute précision est maintenant disponible, et d’autres suivront bientôt.
Un hub documentaire, mis en place début 2025, centralise progressivement les tutoriels et documents techniques d’intérêt général pour NumPEx Exa-DI. Il comprend : le catalogue du logiciel NumPEx, des webinaires et des formations, de la documentation sur la co-conception et le packaging CDT, et bien d’autres choses encore.
N’hésitez pas à le consulter pour vous tenir au courant des outils et des ressources disponibles.
Figure : Vue d’ensemble d’Impact-HPC.
PEPR NumPEx

Exa-DI : Faciliter le déploiement d'applications HPC avec les Package Managers
Exa-DI est fier de présenter sa série de formations destinées aux utilisateurs de package managers, conçues pour optimiser leur expérience d’utilisation.
Le déploiement et le portage d’applications sur des supercalculateurs reste une tâche complexe et fastidieuse. NumPEx encourage les utilisateurs à utiliser des gestionnaires de paquets, permettant un contrôle précis et direct de leur pile logicielle, avec un accent particulier sur Guix et Spack.
Une série de cours de formation et d’événements de soutien a été organisée pour aider les utilisateurs :
– Tutoriel : Introduction à Guix – Octobre 2025
– Tutoriel @ Compass25 : Guix-deploy – Juin 2025
– Coding session : Publication de paquets sur Guix-Science – Mai 2025
– Tutoriel : Spack pour les débutants (en ligne) – Avril 2025
– Tutoriel : Utiliser Guix et Spack pour déployer des applications sur des supercalculateurs – Février 2025
Le passage à de nouvelles méthodes de déploiement prend du temps. NumPEx soutient les utilisateurs en proposant des formations, une assistance, un packaging logiciel, des améliorations d’outils et des partenariats avec des centres de calcul pour optimiser l’expérience de l’utilisateur.
Pour plus d’informations : https://numpex-pc5.gitlabpages.inria.fr/tutorials/webinar/index.html
Crédit photo : Mohammad Rahmani / Unsplash

Exa-DI : la co-conception et le co-développement dans NumPEx progressent
La mise en œuvre du processus de co-conception et co-développement au sein de NumPEx est un des objectifs d’Exa-DI, pour la production de logiciel augmenté et productif. Pour cela, Exa-DI a organisé trois groupes de travail ouvert à tous les membres de NumPEx.
Le projet Exa-DI est chargé de mettre en œuvre le processus de co-conception et de co-développement au sein de NumPEx, dans le but de produire des logiciels exascales augmentés et productifs, orientés vers la science. Dans ce contexte, Exa-DI a déjà organisé trois ateliers: un sur la discrétisation efficace pour les EDP exascales, un autre sur l’AMR structuré par blocs à l’échelle exascale et un troisième sur l’intelligence artificielle pour le HPC exascale. Ces ateliers de deux jours en personne ont rassemblé des membres d’Exa-DI, des membres d’autres projets NumPEx, des équipes présentant des applications issues de divers secteurs de la recherche et de l’industrie, ainsi que des experts.
Les discussions ont porté sur les points suivants
-
- Défis liés au processus de co-conception et de co-développement
- Questions clés
- Les questions les plus urgentes pour le développement collectif et le renforcement des liens entre NumPEx et les applications
- Initiatives visant à promouvoir la durabilité des logiciels exascales et la portabilité des performances.
Un résultat très intéressant et stimulant a été la création de groupes de travail axés sur un ensemble de mini-applications partagées et bien spécifiées représentant les modèles transversaux de calcul et de communication identifiés. Plusieurs équipes d’application ont exprimé leur intérêt à participer à ces groupes. À ce jour, quatre groupes de travail sont activement engagés dans la co-conception et le co-développement de mini-applications, en vue d’intégrer et d’évaluer les ensembles logiques de composants logiciels développés dans les projets NumPEx.
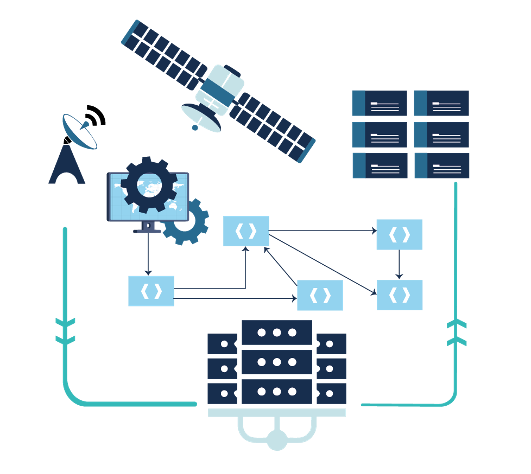
Stratégie pour l’interopérabilité des infrastructures numériques scientifiques
L’évolution des volumes de données et des capacités de calcul est en train de remodeler le paysage numérique scientifique. Pour exploiter pleinement ce potentiel, NumPEx et ses partenaires développent une stratégie d’interopérabilité ouverte reliant les principaux instruments, centres de données et infrastructures de calcul.
Porté par la production des données issues des grands instruments (télescopes, satellites, etc.) et de l’intelligence artificielle, le paysage numérique scientifique connaît une transformation profonde, alimentée par l’évolution rapide des capacités de calcul, de stockage et de communication. Le potentiel scientifique de cette révolution, intrinsèquement multidisciplinaire, repose sur la mise en œuvre de chaînes hybrides de calcul et de traitement, intégrant de manière croissante les infrastructures HPC, les centres de données et les grands instruments.
Anticipant l’arrivée de la machine Exascale Alice Recoque, les partenaires et collaborations de NumPEx (SKA-France, MesoCloud, PEPR Numpex, Data Terra, Climeri, TGCC, Idris, Genci) ont décidé de coordonner leurs efforts afin de proposer des solutions d’interopérabilité, permettant le déploiement de chaînes de traitement exploitant pleinement l’ensemble des infrastructures de recherche.
Les travaux ont pour objectif de définir une stratégie ouverte de mise en œuvre de solutions d’interopérabilité, en lien avec les grands instruments scientifiques, afin de faciliter l’analyse des données et de renforcer la reproductibilité des résultats.
Figure: Overview of Impact-HPC.
© PEPR NumPEx

Impacts-HPC : une bibliothèque Python pour mesurer et comprendre l'empreinte environnementale du calcul scientifique
L’empreinte environnementale du calcul scientifique va bien au-delà de la consommation d’électricité. Impacts-HPC présente un cadre complet pour évaluer les impacts du HPC sur l’ensemble de son cycle de vie, de la fabrication des équipements à la consommation d’énergie, au moyen d’indicateurs environnementaux clés.
L’empreinte environnementale des calculs scientifiques est souvent réduite à la consommation électrique pendant l’exécution. Or, cela ne reflète qu’une partie du problème. Impacts-HPC vise à dépasser cette vision limitée en intégrant aussi l’impact de la fabrication des équipements et en élargissant le spectre des indicateurs considérés.
Cet outil permet également de tracer les étapes d’un workflow de calcul et de documenter les sources utilisées, renforçant ainsi la transparence et la reproductibilité. Dans un contexte où la crise environnementale nous oblige à considérer simultanément climat, ressources et autres frontières planétaires, disposer de tels outils devient indispensable.
La librairie Impacts-HPC couvre plusieurs étapes du cycle de vie : fabrication et usage des équipements. Elle fournit aux utilisateurs trois indicateurs essentiels :
- Énergie primaire (MJ) : plus pertinent que la seule électricité, car il inclut les pertes de conversion tout au long de la chaîne énergétique.
- Impact climatique (gCO₂eq) : calculé par l’agrégation et la conversion des différents gaz à effet de serre en équivalents CO₂.
- Déplétion des ressources (g Sb eq) : reflétant l’utilisation de ressources non renouvelables, en particulier les minerais métalliques et non métalliques.
C’est la première fois qu’un tel outil est proposé pour un usage direct par les communautés du calcul scientifique, avec une approche intégrée et documentée.
Cette librairie ouvre la voie à une évaluation plus fine des impacts environnementaux liés au calcul scientifique. Les prochaines étapes incluent son intégration dans des environnements de type jumeau numérique, l’ajout de données en temps réel (mix énergétique, stockage, transferts), ainsi que des tests sur un centre HPC de référence (IDRIS). De nouveaux indicateurs, tels que la consommation d’eau, pourront venir compléter l’outil pour en faire une brique incontournable de l’évaluation environnementale du calcul haute performance.
Figure: Overview of Impact-HPC.
© PEPR NumPEx
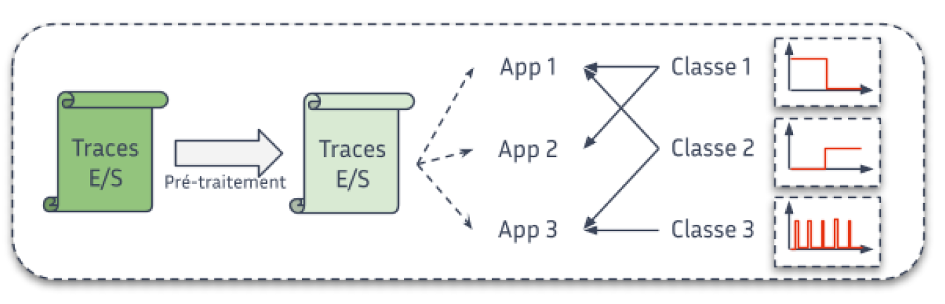
Stockage de volumes massifs de données : mieux comprendre pour mieux concevoir et optimiser
Il est essentiel de comprendre comment les applications scientifiques lisent et écrivent les données pour concevoir des systèmes de stockage qui répondent réellement aux besoins du calcul intensif. La caractérisation fine des E/S permet d’orienter les stratégies d’optimisation et l’architecture des futures infrastructures de stockage.
Les données sont au cœur des applications scientifiques, qu’il s’agisse des données en entrées ou des résultats de traitements. Depuis plusieurs années, leur gestion (lecture et écriture, aussi appelées E/S) est un frein au passage à très large échelle de ces applications. Afin de concevoir des systèmes de stockage plus performants capables d’absorber et d’optimiser ces E/S, il est indispensable de comprendre comment les applications lisent et écrivent ces données.
Grâce aux différents outils et méthodes que nous avons développés, nous sommes capables de produire une caractérisation fine du comportement E/S des applications scientifiques. Par exemple, à partir des données d’exécution de supercalculateurs, nous pouvons montrer que moins d’un quart des applications effectuent des accès réguliers (périodiques) ou encore que les accès concurrents sur le système de stockage principal sont moins courants qu’attendus.
Ce type de résultat est déterminant à plusieurs titres. Il permet par exemple de proposer des méthodes d’optimisation des E/S qui répondent à des comportements clairement identifiés des applications. Une telle caractérisation est aussi un élément concret pour influencer les choix de conceptions de futurs systèmes de stockage, toujours dans le but de répondre aux besoins des applications scientifiques.
Figure : Étape de la classification des données.
PEPR NumPEx

Une nouvelle génération de bibliothèques d'algèbre linéaire pour les superordinateurs modernes
Les bibliothèques d’algèbre linéaire sont au cœur du calcul scientifique et de l’intelligence artificielle. En repensant leur exécution sur les architectures hybrides CPU/GPU, de nouvelles approches à base de tâches dynamiques permettent d’en améliorer significativement les performances et la portabilité.
Les bibliothèques de résolution ou de manipulation de systèmes linéaires sont utilisées dans de nombreux domaines de la simulation numérique (aéronautique, énergie, matériaux) et de l’intelligence artificielle (training). Nous cherchons à rendre ces bibliothèques les plus rapides possibles sur les supercalculateurs combinant processeurs traditionnels et accélérateurs graphiques (GPU). Nous utilisons pour cela des modèles d’exécution à base de tâches asynchrones qui maximisent l’occupation des unités de calcul.
C’est un domaine de recherche actif où la plupart des approches existantes se heurtent toutefois au difficile problème de découpage du travail « à la bonne granularité » pour des unités de calcul qui sont hétérogènes.
Durant les derniers mois nous avons mis au point plusieurs extensions d’un modèle de programmation parallèle à base de tâches dit STF (Sequential Task Flow) qui permet d’implémenter de manière beaucoup plus élégante, concise et portable des algorithmes complexes. En combinant ce modèle avec des techniques de découpage dynamique et récursif du travail, on accroît significativement les performances sur des supercalculateurs équipés d’accélérateurs tels que des GPU, notamment grâce à la capacité d’adapter dynamiquement la granularité des calculs en fonction de l’occupation des unités de calcul. A titre d’exemple, grâce à cette approche nous avons obtenu une accélération de 2x par rapport à d’autres bibliothèques de l’état de l’art (MAGMA, Parsec) sur un calculateur hybride CPU/GPU.
Les opérations d’algèbre linéaire sont souvent les étapes les plus coûteuses dans de nombreuses applications de calcul scientifique, analyse de données et apprentissage profond. Par conséquent, toute amélioration de performances dans les bibliothèques d’algèbre linéaire peut potentiellement avoir un impact significatif pour de nombreux utilisateurs de ressource de calcul à haute performance.
Les extensions proposées du modèle STF sont génériques et peuvent également bénéficier à nombreux codes de calcul au-delà du périmètre de l’algèbre linéaire.
Dans la prochaine période, nous souhaitons étudier l’application de cette approche aux algorithmes d’algèbre linéaire pour matrices creuses ainsi qu’aux algorithmes d’algèbre multi-linéaire (calculs tensoriels).
Adapter la granularité permet de confier aux CPUs des tâches plus petites qui ne les occuperont pas trop longtemps, ce qui évite de faire attendre le reste de la machine, tout en continuant à confier aux GPUs de grandes tâches pour qu’ils restent efficaces.
Figure : Adapter la granulométrie permet de confier aux CPUs des tâches plus petites qui ne les occuperont pas trop longtemps, ce qui évite de faire attendre le reste de la machine, tout en continuant à confier aux GPUs de grandes tâches pour qu’ils restent efficaces.
© PEPR NumPEx