


Result of the NumPEx call for action
The NumPEx program is launching its first call for projects to support advances in high-performance computing (HPC), high-performance data analysis (HPDA) and artificial intelligence (AI). Our France 2030 research program aims to develop software capable of operating future exascale machines, and to prepare the main scientific and industrial application codes.
This call is structured around three axes:
- Emerging AI methods, algorithms and software for scientific computing and HPC for AI.
- Programming models adapted to accelerated architectures.
- Workflows for scientific data analysis, with the SKA project as a use case.
DAIMOS - Distributed AI Model training Optimization at Scale
Project leader: Julien Herrmann, CNRS researcher
Training large-scale AI models presents major challenges, particularly regarding computational
cost and energy efficiency. This project addresses these issues by developing a new software stack
for large-scale deep learning, based on a close integration of algorithmic advances, systems-level
optimization, and concrete application use cases. It directly supports the priorities of the NumPEx
PEPR program on HPC for AI.
SAGe-HPC - Smart strateGies for multi-fidelity optimization in Exascale HPC Environments
Project leader: Laëtitia Giraldi, Inria researcher
The SAGE-HPC project aims to develop a scalable, open, and interoperable software platform for multifidelity
optimization of complex physical problems in exascale high-performance computing (HPC) environments.
Solving such optimization problems poses a major scientific challenge due to the complexity
of the physical phenomena involved and the computational cost associated with high-fidelity simulations.
To overcome this challenge, the project leverages both the coordinated use of variable-fidelity models —
where simplified, low-cost models guide the exploration of the solution space, and high-fidelity models are
used selectively to refine the results — and the massive exploitation of exascale HPC resources, enabling
large-scale parallel processing of these approaches.
KOKTAILS - Kokkos by translation and interoperability leveraged in software
Project leader: Stéphane de Chaisemartin, IFPEN engineer
The KOKTAILS project aims to enhance the portability of simulation software on Exascale computing
architectures, by contributing to the development of a sovereign software stack adapted to
GPU-based supercomputers. It is part of the NumPEx PEPR strategy and contributes to French
digital sovereignty in high-performance computing (HPC). It includes the development of scalable
middleware to guarantee performance portability on various GPU architectures, including European
processors such as SiPearl Rhea. The project thus contributes to the transition of existing applications
to Exascale computing, through the creation of an open-source ecosystem in line with
European sovereignty policy.
ASTRA - Advanced FR-SRC Tasks and Resource Allocation
Project leader: Marc-Antoine Miville-Deschênes, CNRS researcher
This research project addresses the critical transformation underway in radio astronomy, driven by next-generation observatories such as LOFAR2.0 and the SKA. These instruments are producing massive, heterogeneous datasets distributed across multiple sites, which cannot be efficiently handled using legacy data processing approaches. The project aims to overcome these structural bottlenecks by developing a unified, scalable digital platform that federates HPC, cloud, and object storage resources. It will support the execution of complex workflows (including AI-based processing) across heterogeneous infrastructures through modern containerization technologies. Key principles such as data provenance, reproducibility, and energy-aware computing will be integrated to support both interactive and automated scientific workflows.
Trans Numériques 2026
The PEPR NumPEx was proud to participate in the first edition of Trans Numériques! Thirteen PEPRs gathered from 2 to 5 February at the Couvent des Jacobins in Rennes to share scientific advances and challenges relating to performance, security, frugality and the societal impact of the digital continuum.
This event was an opportunity for NumPEx to come together to reflect on the programme’s next milestones, particularly on three major themes: IA and HPC convergence, software ecosystem and digital continuum. At the same time, this event provided an opportunity to exchange ideas with other PEPRs and share inter-PEPR projects with the digital community.
Finally, we are really proud of Méline Trochon and Théo Jolivel, NumPEx PhD students, who represented NumPEx in the ANR video and shared their fresh perspective on the event!
NumPEx program
Tuesday, 3 February 2026
- Introduction to the NumPEx only sessions
- IA and HPC convergence
- Software ecosystem
- Digital continuum
Wednesday, 4 February 2026
- IA and HPC convergence – workshop
- Software ecosystem – workshop
- Digital continuum – workshop
Thursday, 5 February 2026
- Workshop restitution
© Thomas Crabot
The ANR movie of the event

The first YoungPEx general meeting
The YoungPEx committee is an initiative from NumPEx to bring together young researchers together to discuss the future of high-performance computing and open science. This event was an important first step to energize the committee and talk about topics that will be key in the future. Various workshops were organized:
- A workshop on the environmental impact of HPC
led by Georges Da Costa, Université de Toulouse professor and Exa-SoFt member - A general assembly to discuss the YoungPEx committee’s upcoming actions and the renewal of organizing members
- A workshop on the theme of social and gender inequalities
Wednesday, 12 November 2025
This first day of workshop was led by Georges Da Costa, Université de Toulouse professor and Exa-SoFt member
Thursday, 13 November 2025
This second day was the occasion to go further on the first day topics.
The afternoon was dedicated to gather the members of the community, exchange on their works by many activities:
- Antithèse: Four presentations were prepared before the day, and four participants volunteered to present it, by discovering the slides 5 minutes before the presentation.
- Start-up nation: the participants were split into four groups and should create a pitch of a strat-up, or a research project, that would gather the interest of all the members
- Feedback on the workshop, and emergence of ideas
- Ideas for the futures actions of YoungPEx.
Friday, 14 November 2025
On the last day, the main topic was the Equity and Equality in Science. Three different sessions were organized:
- the Monopoly of inequalities, a game inspired by the famous Monopoly, meant to highlight that everyone doesn’t have the same chance to succeed, hosted by Yasmina Asso from the Observatory of Inequiality;
- A presentation by Julie Lesthelle, from Université de Bordeaux, of the results of her master thesis entitled Les études en licence de mathématiques sous le prisme du genre : Construction d’un environnement masculin et expériences des étudiantes en situation minoritaire.
- A round table about the concept of leaking pipeline, with the intervention of Elsa Cazelles (Chargée de Recherche at IRIT), Sylvie Chambon (Professeure des Universités à ENSEEIHT), Julie Lesthelle (student at Université de Bordeaux), Lucie Baudouin (Directrice de Recherche at LASS) and Aline Roc (research ingeneer at CATIE).
These sessions addressed a state of the art on the matter of equality and equality, and and produced some recommendations and warning signs to identify or prevent further inequalities in the NumPEx community.
Organising committee
- Thomas Saigre, Inria postdoctorant at IRMA and Exa-MA member
- Karmijn Hoogveld, CNRS doctorant at IRIT and Exa-SofT member
- Méline Trochon, Inria doctorant at LaBRI and Exa-DoST
- Mathis Certenais, doctorant of the Université de Rennes at Irisa and Exa-AtoW member
- Romain Garbage, Inria engineer and Exa-DI member
The organizers would like to thanks all the participants to this event, as well as Georges Da Costa, Yasmina Asso, Julie Lesthelle, Elsa Cazelles, Sylvie Chambon, Lucie Beaudouin and Aline Roc for their time and their participation to the different activties !



© Karmijn Hoogveld, Alfredo Buttari
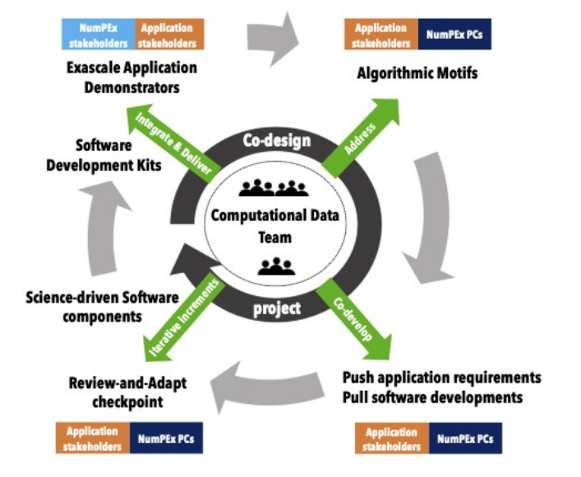
Exa-DI: the first mini-application resulting from co-development is now available!
Following the Exa-DI general meetings, working groups were formed to produce applications on four major themes. The first mini application on high-precision discretisation is now available.
Following the Exa-DI workshops, four working groups (WGs) were formed, bringing together all the players involved in co-design and co-development: Exa-DI’s Computational and Data Science (CDT) team, members of the various targeted NumPEx projects, and application demonstration teams. These groups focus on efficient discretisation, unstructured meshes, block-structured AMR, and AI applied to linear inverse problems at exascale, and are now actively moving forward.
Thanks to these WGs, the first shared mini-applications, representative of the technical challenges of exascale applications, are currently being developed. They integrate high value-added software components (libraries, frameworks, tools) provided by other NumPEx teams. In this context, the first mini-application on high-precision discretisation is now available, with others to follow soon.
A documentation hub, set up in early 2025, is gradually centralising tutorials and technical documents of general interest for NumPEx Exa-DI. It includes: the NumPEx software catalogue, webinars and training courses, documentation on co-design and CDT packaging, and much more.
Feel free to consult it to stay up to date on the tools and resources available.
Figure: Overview of Impact-HPC.
© PEPR NumPEx

Exa-DI: Facilitating the deployment of HPC applications with Package Managers
Exa-DI is proud to present its series of training courses for users of package managers, designed to optimise their user experience.
Deploying and porting applications on supercomputers remains a complex and time-consuming task. NumPEx encourages users to leverage package managers, allowing for precise and direct control of their software stack, with a particular focus on Guix and Spack.
A series of training courses and support events has been organised to assist users:
• Tutorial: Introduction to Guix – October 2025
• Tutorial @ Compass25: Guix-deploy – June 2025
• Coding session: Publishing packages on Guix-Science – May 2025
• Tutorial: Spack for beginners (online) – April 2025
• Tutorial: Using Guix and Spack for deploying applications on supercomputers – February 2025
Switching to new deployment methods takes time. NumPEx supports users by offering training, support, software packaging, tool improvements, and partnerships with computing centres to optimise the user experience.
For more information: https://numpex-pc5.gitlabpages.inria.fr/tutorials/webinar/index.html
Photo credit: Mohammad Rahmani / Unsplash

Exa-DI: the co-design and co-development in NumPEx is moving forward
The implementation of the co-design and co-development process within NumPEx is one of Exa-DI’s objectives for the production of augmented and productive software. To this end, Exa-DI has organised three working groups open to all NumPEx members.
The Exa-DI project is responsible for implementing the co-design and co-development process within NumPEx, with the aim of producing augmented and productive exascale software that is science-driven. In this context, Exa-DI has already organised three workshops: one on “Efficient discretisation for exascale EDPs”, another on “Block-structured AMR at exascale” and a third on “Artificial intelligence for exascale HPC”. These two-day in-person workshops brought together Exa-DI members, members of other NumPEx projects, teams demonstrating applications from various sectors of research and industry, and experts.
Discussions focused on:
-
- Challenges related to the co-design and co-development process
- Key issues
- The most pressing issues for collective development and strengthening links between NumPEx and applications
- Initiatives promoting the sustainability of exascale software and performance portability.
A very interesting and stimulating result was the establishment of working groups focused on a set of shared and well-specified mini-applications representing the cross-cutting computational and communication patterns identified. Several application teams have expressed interest in participating in these groups. To date, four working groups are actively engaged in the co-design and co-development of mini-applications, with a view to integrating and evaluating the logical sets of software components developed in the NumPEx projects.
Strategy for the interoperability of digital scientific infrastructures
The evolution of data volumes and computing capabilities is reshaping the scientific digital landscape. To fully leverage this potential, NumPEx and its partners are developing an open interoperability strategy connecting major instruments, data centers, and computing infrastructures.
Driven by data produced by large instruments (telescopes, satellites, etc.) and artificial intelligence, the digital scientific landscape is undergoing a profound transformation, fuelled by rapid advances in computing, storage and communication capabilities. The scientific potential of this inherently multidisciplinary revolution lies in the implementation of hybrid computing and processing chains, increasingly integrating HPC infrastructures, data centres and large instruments.
Anticipating the arrival of the Alice Recoque exascale machine, NumPEx’s partners and collaborators (SKA-France, MesoCloud, PEPR NumPEx, Data Terra, Climeri, TGCC, Idris, Genci) have decided to coordinate their efforts to propose interoperability solutions that will enable the deployment of processing chains that fully exploit all research infrastructures.
The aim of the work is to define an open strategy for implementing interoperability solutions, in conjunction with large scientific instruments, in order to facilitate data analysis and enhance the reproducibility of results.
Figure: Overview of Impact-HPC.
© PEPR NumPEx

Impacts-HPC: a Python library for measuring and understanding the environmental footprint of scientific computing
The environmental footprint of scientific computing goes far beyond electricity consumption. Impacts-HPC introduces a comprehensive framework to assess the full life-cycle impacts of HPC, from equipment manufacturing to energy use, through key environmental indicators.
The environmental footprint of scientific computing is often reduced to electricity consumption during execution. However, this only reflects part of the problem. Impacts-HPC aims to go beyond this limited view by also incorporating the impact of equipment manufacturing and broadening the spectrum of indicators considered.
This tool also makes it possible to trace the stages of a computing workflow and document the sources used, thereby enhancing transparency and reproducibility. In a context where the environmental crisis is forcing us to consider climate, resources and other planetary boundaries simultaneously, such tools are becoming indispensable.
The Impacts-HPC library covers several stages of the life cycle: equipment manufacturing and use. It provides users with three essential indicators:
• Primary energy (MJ): more relevant than electricity alone, as it includes conversion losses throughout the energy chain.
• Climate impact (gCO₂eq): calculated by aggregating and converting different greenhouse gases into CO₂ equivalents.
• Resource depletion (g Sb eq): reflecting the use of non-renewable resources, in particular metallic and non-metallic minerals.
This is the first time that such a tool has been offered for direct use by scientific computing communities, with an integrated and documented approach.
This library paves the way for a more detailed assessment of the environmental impacts associated with scientific computing. The next steps include integrating it into digital twin environments, adding real-time data (energy mix, storage, transfers), and testing it on a benchmark HPC centre (IDRIS).
Figure: Overview of Impact-HPC.
© PEPR NumPEx
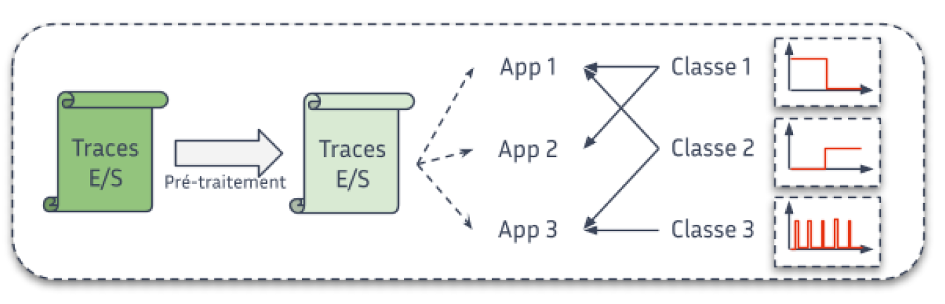
Storing massive amounts of data: better understanding for better design and optimisation
A understanding of how scientific applications read and write data is key to designing storage systems that truly meet HPC needs. Fine-grained I/O characterization helps guide both optimization strategies and the architecture of future storage infrastructures.
Data is at the heart of scientific applications, whether it be input data or processing results. For several years, data management (reading and writing, also known as I/O) has been a barrier to the large-scale deployment of these applications. In order to design more efficient storage systems capable of absorbing and optimising this I/O, it is essential to understand how applications read and write data.
Thanks to the various tools and methods we have developed, we are able to produce a detailed characterisation of the I/O behaviour of scientific applications. For example, based on supercomputer execution data, we can show that less than a quarter of applications perform regular (periodic) accesses, or that concurrent accesses to the main storage system are less common than expected.
This type of result is decisive in several respects. For example, it allows us to propose I/O optimisation methods that respond to clearly identified application behaviours. Such characterisation is also a concrete element that influences the design choices of future storage systems, always with the aim of meeting the needs of scientific applications.
Figure: Step of data classification.
© PEPR NumPEx

A new generation of linear algebra libraries for modern supercomputers
Linear algebra libraries lie at the core of scientific computing and artificial intelligence. By rethinking their execution on hybrid CPU/GPU architectures, new task-based models enable significant gains in performance, portability, and resource utilization.
Libraries for solving or manipulating linear systems are used in many fields of numerical simulation (aeronautics, energy, materials) and artificial intelligence (training). We seek to make these libraries as fast as possible on supercomputers combining traditional processors and graphics accelerators (GPUs). To do this, we use asynchronous task-based execution models that maximise the utilisation of computing units.
This is an active area of research, but most existing approaches face the difficult problem of dividing the work into the ‘right granularity’ for heterogeneous computing units. Over the last few months, we have developed several extensions to a task-based parallel programming model called STF (Sequential Task Flow), which allows complex algorithms to be implemented in a much more elegant, concise and portable way. By combining this model with dynamic and recursive work partitioning techniques, we significantly increase performance on supercomputers equipped with accelerators such as GPUs, in particular thanks to the ability to dynamically adapt the granularity of calculations according to the occupancy of the computing units. For example, thanks to this approach, we have achieved a 2x speedup compared to other state-of-the-art libraries (MAGMA, Parsec) on a hybrid CPU/GPU computer.
Linear algebra operations are often the most costly steps in many scientific computing, data analysis and deep learning applications. Therefore, any performance improvement in linear algebra libraries can potentially have a significant impact for many users of high-performance computing resources.
The proposed extensions to the STF model are generic and can also benefit many computational codes beyond the scope of linear algebra.
In the next period, we wish to study the application of this approach to linear algebra algorithms for sparse matrices as well as to multi-linear algebra algorithms (tensor calculations).
Adapting granularity allows smaller tasks to be assigned to CPUs, which will not occupy them for too long, thus avoiding delays for the rest of the machine, while continuing to assign large tasks to GPUs so that they remain efficient.
Figure: Adjusting the grain size allows smaller tasks to be assigned to CPUs, which will not take up too much of their time, thus avoiding delays for the rest of the machine, while continuing to assign large tasks to GPUs so that they remain efficient.
© PEPR NumPEx