


Result of the NumPEx call for action
The NumPEx program is launching its first call for projects to support advances in high-performance computing (HPC), high-performance data analysis (HPDA) and artificial intelligence (AI). Our France 2030 research program aims to develop software capable of operating future exascale machines, and to prepare the main scientific and industrial application codes.
This call is structured around three axes:
- Emerging AI methods, algorithms and software for scientific computing and HPC for AI.
- Programming models adapted to accelerated architectures.
- Workflows for scientific data analysis, with the SKA project as a use case.
DAIMOS - Distributed AI Model training Optimization at Scale
Project leader: Julien Herrmann, CNRS researcher
Training large-scale AI models presents major challenges, particularly regarding computational
cost and energy efficiency. This project addresses these issues by developing a new software stack
for large-scale deep learning, based on a close integration of algorithmic advances, systems-level
optimization, and concrete application use cases. It directly supports the priorities of the NumPEx
PEPR program on HPC for AI.
SAGe-HPC - Smart strateGies for multi-fidelity optimization in Exascale HPC Environments
Project leader: Laëtitia Giraldi, Inria researcher
The SAGE-HPC project aims to develop a scalable, open, and interoperable software platform for multifidelity
optimization of complex physical problems in exascale high-performance computing (HPC) environments.
Solving such optimization problems poses a major scientific challenge due to the complexity
of the physical phenomena involved and the computational cost associated with high-fidelity simulations.
To overcome this challenge, the project leverages both the coordinated use of variable-fidelity models —
where simplified, low-cost models guide the exploration of the solution space, and high-fidelity models are
used selectively to refine the results — and the massive exploitation of exascale HPC resources, enabling
large-scale parallel processing of these approaches.
KOKTAILS - Kokkos by translation and interoperability leveraged in software
Project leader: Stéphane de Chaisemartin, IFPEN engineer
The KOKTAILS project aims to enhance the portability of simulation software on Exascale computing
architectures, by contributing to the development of a sovereign software stack adapted to
GPU-based supercomputers. It is part of the NumPEx PEPR strategy and contributes to French
digital sovereignty in high-performance computing (HPC). It includes the development of scalable
middleware to guarantee performance portability on various GPU architectures, including European
processors such as SiPearl Rhea. The project thus contributes to the transition of existing applications
to Exascale computing, through the creation of an open-source ecosystem in line with
European sovereignty policy.
ASTRA - Advanced FR-SRC Tasks and Resource Allocation
Project leader: Marc-Antoine Miville-Deschênes, CNRS researcher
This research project addresses the critical transformation underway in radio astronomy, driven by next-generation observatories such as LOFAR2.0 and the SKA. These instruments are producing massive, heterogeneous datasets distributed across multiple sites, which cannot be efficiently handled using legacy data processing approaches. The project aims to overcome these structural bottlenecks by developing a unified, scalable digital platform that federates HPC, cloud, and object storage resources. It will support the execution of complex workflows (including AI-based processing) across heterogeneous infrastructures through modern containerization technologies. Key principles such as data provenance, reproducibility, and energy-aware computing will be integrated to support both interactive and automated scientific workflows.

The 2026 annual meeting of Exa-DI
The 2026 annual meeting of the Exa-DI project (Development and Integration) of the PEPR NumPEx took place on February 24 and 25th at Espace Trinité, Paris.
This face-to-face meeting brought together for one day the complete Exa-DI team – the members of each Work Package (WPs), the Program manager of the CDT, the CDT members, the leaders of the co-design/co-development Working groups (WGs) who are member of the Application Demonstrators (ADs) teams, members of others NumPEx projects of the (Exa-MA, Exa-SofT, Exa-DoST and Exa-AToW), as well as representatives from the national (IDRIS, TGCC, CINES) and regional (GriCAD,) computing centres and experts.
This meeting was first an opportunity to create the momentum between all the stakeholders involved in the co-design/co-development processes and second tostrengthen their alignment. This is one of the main objectives of the Backlog sessions in which each co-design/co-development working groups (WGs) presented their roadmap for the next 2-3 month in order to establish, coordinate and organize the engineering activities of the CDT development team. Given the importance and cross-cutting nature of the topic across NumPEx, a presentation on «Task-based programming and its applications » was given by a leading expert from the Exa-SofT project. The Software packaging and deployment session organized with the participation of a regional (GriCAD) and all national computing centres (TGCC, IDRIS and CINES) provides the opportunity to discuss about packaging solutions (e.g., modules, Spack, Guix) with the aim of supporting code developers to port and deploy applications on various architectures, and in particular on leading exascale architectures. The CDT session provide an overview of the current engineering activities of the development CDT team given through four presentations, i.e Infrastructure for Benchmarking, Guix-Based Deployment and unified Kokkos Integration, High-Performance Spectral Element Operators on GPUs and Benchmarking Large Scale Inverse Problems Resolution Algorithms with Benchopt, which was followed by general discussions. Finally, in light of the recent workshop organized by GENCI following Alice Recoque’s procurement February 17-19, 2026), where collaborations between NumPEx, Bull and AMD were discussed, a specific session on possible Exa-DI/AMD/Bull collaborations was organized to, on the one hand, give feedback on the Bull/AMD workshop and, on the other hand, discuss the actions to be implemented to identify and start collaborations with AMD and Bull.
One of main goal of this meeting has been to brainstorm all together on collaboration patterns supporting the ramp-up of the Exa-DI project and their implementation through the co-design/co-development structures set-up in Exa-DI: the CDT, the co-design/co-development WGs, the WPs, etc. A key point was to follow and check that the articulation and coordination of these different structures were carried out correctly and allowed to ensure the co-design/co-development process’s success. This is essential in order to prepare the porting of applications to exascale architectures and in particular to the next European leading exascale facility to be installed at the TGCC, Alice Recoque and open to users by the end of 2027.
This annual meeting of the project is crucial to monitor that the project was being conducted properly and to ensure the proper coordination of engineering and packaging activities within the CDT in collaboration with all the stakeholders, a key point of the co-design and co-development process.
Highlights on the different components of the co-design/co-development process such as the roadmap of the co-design/co-development WGs, the engineering activities of the CDT development team, the software packaging and deployment activities of the CDT enabling team allowed to demonstrate the paramount importance of all these different activities to implement and achieve the co-design and co-development process as well as of the collaborations in the day-to-day reseach & engineering activities. The discussions with the national and regional computing centers clarified the various current and future solutions for software packaging and deployment in the regional and national computing centers and highlighted what will need to be implemented in view of the heterogeneity of future architectures. Moreover, all participants in this session agreed to meet again in the future to keep each other informed of developments and to discuss them together. Overall, the discussions were very fruitful and showed there is a strong motivation and interest in reinforcing collaborations between all the stakeholders involved in the co-design/co-development processes, and avoiding as much as possible silos & work in isolation.
Tuesday, 24 February 2026
- Introduction
by Valérie Brenner, CEA research scientist - Backlog session
by Jérôme Charousset, CEA engineer- Roadmap Working group (WG) 1
by Henri Calandra, Expert numerical methods and High Performance Computing at TotalEnergies - Roadmap WG2
by Julien Vanharen, Inria research scientist - Roadmap WG3
Maxime Delorme, CEA research scientist - Roadmap WG4
Thomas Moreau, Inria research scientist
- Roadmap Working group (WG) 1
- Programmation par tâches et ses applications
by Samuel Thibault, professor at Bordeaux University - Sofware packaging and deployment session
by Benoît Martin, Sorbonne University research scientist- Software packaging and deployment in Exa-DI
by Benoît Martin, Sorbonne University research scientist
and Bruno Raffin, Inria research scientist - Software packaging and deployment at GriCAD
by Pierre-Antoine Bouttier, CNRS engineer - Software packaging and deployment at TGCC
by Xavier Delaruelle, CEA manager and Laurent Nguyen, CEA engineer - Software packaging and deployment at IDRIS
by Remi Lacroix, CNRS engineer - Software packaging and deployment at CINES
by Gabriel Hautreux, HPC expert at CINES
- Software packaging and deployment in Exa-DI
Wednesday, 25 February 2026
- CDT session
by Félix Kpadonou, CEA research scientist- Infrastructure for Benchmarking
by Jérôme Charousset, CEA engineer - Guix-Based Deployment and unified Kokkos Integration
by Aurélien Dauteuil, CEA engineer - High-Performance Spectral Element Operators on GPUs
by Alexandre Roger, CNRS - Benchmarking Large Scale Inverse Problems Resolution Algorithms with Benchopt
by Benoit Malézieux, CNRS research scientist
- Infrastructure for Benchmarking
- AMD collaborations session
by Jérôme Bobin, CEA research scientist
Attendees
- Juliette Antonczack, Exa-MA, Université de Strasbourg
- Alexis Badel, Inria
- Rémi Baron, Exa-DI, CEA
- Baptiste Besnard, CNRS
- Julien Bigot, Exa-DI, Inria
- Jérôme Bobin, Exa-DI, CEA
- Pierre-Antoine Bouttier, CNRS
- Thomas Bouvier, Exa-DI, CEA
- Eric Boyer, Genci
- Valérie Brenner, Exa-DI, CEA
- Henri Calandra, AD, TotalEnergies
- Ansar Calloo, Exa-MA, CEA
- Mathieu Certenais, Exa-AToW, Université Rennes
- Aurélien Citrain, Inria
- Jérôme Charousset, Exa-DI, CEA
- Javier Cladellas, Exa-MA, Université Strasbourg
- Ludovic Courtes, Exa-DI, Inria
- Aurélien Dauteuil, Exa-DI, CEA
- Xavier Delaruelle, CEA
- Romain Denelle, EDF
- Maxime Delorme, AD, CEA
- Etienne Decossin, EDF
- Triem Phan Dinh, Exa-DI, CNRS
- Romain Garbage, Exa-DI, Inria
- Damien Gradatour, Exa-DoST, CNRS
- Virginie Grangirard, Exa-DoST, CEA
- Loïc Guoarin, Exa-MA, École Polytechnique
- Gabriel Hautreux, Université de Montpellier
- Skander Khiari, Exa-DI, CEA
- Chai Koren, EDF
- Félix Kpadonou, Exa-DI, CEA
- Rémi Lacroix, CNRS
- Pierre-François Lavallée, CNRS
- Guillaume Lechantre, Genci
- Benoît Malézieux, Exa-DI, CNRS
- Benoît Martin, Exa-DI, CEA
- Marc Antoine Miville-Deschênes, CNRS
- Thomas Moreau, GT IA, CEA
- Laurent Nguyen, CEA
- Augustin Parret-Freaud, Safran Tech
- Bruno Raffin, Exa-DI, Inria
- Alexandre Roger, Exa-DI, CNRS
- Pascal Tremblin, CEA
- Samuel Thibaut, Exa-SofT, Inria
- Jean-Pierre Vilotte, Exa-DI, CNRS
- Julien Vanharen, AD, Inria





© PEPR NumPEx
Trans Numériques 2026
The PEPR NumPEx was proud to participate in the first edition of Trans Numériques! Thirteen PEPRs gathered from 2 to 5 February at the Couvent des Jacobins in Rennes to share scientific advances and challenges relating to performance, security, frugality and the societal impact of the digital continuum.
This event was an opportunity for NumPEx to come together to reflect on the programme’s next milestones, particularly on three major themes: IA and HPC convergence, software ecosystem and digital continuum. At the same time, this event provided an opportunity to exchange ideas with other PEPRs and share inter-PEPR projects with the digital community.
Finally, we are really proud of Méline Trochon and Théo Jolivel, NumPEx PhD students, who represented NumPEx in the ANR video and shared their fresh perspective on the event!
NumPEx program
Tuesday, 3 February 2026
- Introduction to the NumPEx only sessions
- IA and HPC convergence
- Software ecosystem
- Digital continuum
Wednesday, 4 February 2026
- IA and HPC convergence – workshop
- Software ecosystem – workshop
- Digital continuum – workshop
Thursday, 5 February 2026
- Workshop restitution
© Thomas Crabot
The ANR movie of the event

The 2026 annual meeting of Exa-MA
The 2026 Exa-MA Annual Assembly held at Arts et Métiers ParisTech (Aix-en-Provence) from 19 to 21 January, 2026, highlighted the project’s central role in France’s NumPEx initiative. It focused on preparing the software stack for the “Alice Recoque” exascale supercomputer.
Exa-MA aims to revolutionize methods and algorithms for exascale scaling: discretization, resolution, learning and order reduction, inverse problem, optimization and uncertainties. We are contributing to the software stack of future European computers.
The 3rd Exa-MA General Assembly highlighted the project’s central role in France’s NumPEx initiative, preparing the software stack for the “Alice Recoque” exascale supercomputer. Key discussions focused on 2026 priorities: GPU portability, AI-driven HPC convergence, and real-time neural operators, with applications in fusion energy, climate modeling, and aeronautics. The assembly emphasized delivering sovereign, open, and reproducible solutions, while addressing challenges like AI reliability in HPC and GPU acceleration. By expanding training and demonstrators, Exa-MA is reinforcing its “French model” of collaborative innovation, bridging AI and HPC for measurable scientific and societal impact.
Monday, 19 January 2026
- General presentation of NumPEx & Exa-MA
- Presentations of WPs: progress made + scientific highlights + next steps
Wednesday, 21 2026
- Presentation of Sage-HPC (AI for HPC)
- Presentation of Daimos (HPC for AI)
- Feedbacks from WPs (intra-WP meetings + breakout sessions with frameworks):
Attendees
- Emmanuel Agullo, Inria
- Pierre Alliez, Inria
- Amaury Bélières Frendo, Unistra
- Ani Anciaux Sedrakian, IFPEN
- Brieuc Antoine dit Urban, Inria
- Juliette Antonczak, Unistra
- Mark Asch, Université de Picardie
- Hassan Ballout, Unistra
- Helene Barucq, Inria
- Jerome Bobin, CEA
- Jed Brown, University of Colorado
- Filippo Brunelli, Inria
- Ansar Calloo, CEA
- Xinye Chen, Sorbonne Université
- Javier Cladellas, Unistra
- Susanne Claus, ONERA
- Ariel De Vora, CEA
- Mohamed Doumbouya, Inria
- Pierre Dubois, CEA
- Mahmoud El khadiri, Inria
- Erik Fabrizzi, Sorbonne Université
- Vincent Faucher, CEA
- Emmanuel Franck, Inria
- Josselin Garnier, Ecole Polytechnique
- Clément Gauchy, CEA
- Christophe Geuzaine, Université de Liège
- Laetitia Giraldi, Inria
- Loic Gouarin, Ecole Polytechnique
- Arthur Gouinguenet, Inria
- Virginie Grandgirard, CEA
- Julien Herrmann, Inria
- Alexandre Hoffmann, Ecole Polytechnique
- Remy Hosseinkhan, Ecole Polytechnique
- Daria Hrebenshchykova, Inria
- Bertrand Iooss, EDF
- Vincent Italiano, Unistra
- Utpal Kiran, CEA
- Félix Kpadonou, CEA
- Philipp Krah, CEA
- Stéphane Lanteri, Inria
- Romain Le Tellier, CEA
- Benoît Malézieux, CEA
- Gilles Marait, Inria
- Jean-Baptiste Mascary, ANR
- Lois McInnes, Argonne National Laboratory
- Victor Michel-Dansac, Inria
- Mahamat Hamdan Nassouradine, CEA
- Frédéric Nataf, Sorbonne Université
- Laurent Navoret, Unistra
- Lars Nerger, Alfred Wegener Institute
- Augustin Parret-Fréaud, Safran
- Lucas Pernollet, CEA
- Raphaël Prat, CEA
- Christophe Prud’homme, Unistra
- Isabelle Ramière, CEA
- Yves Robert, ENS
- Mael Rouxel-Labbe, Geometry Factory
- Gianluigi Rozza, SISSA
- Eric Savin, ONERA
- Lukas Spies, Inria
- Alexandre Tabouret, Sorbonne Université
- El-ghazali Talbi, Université de Lille
- Tom Caruso, Inria
- Sébastien Tordeux, Inria
- Arthur Vidard, Inria
- Jean-Pierre Vilotte, CNRS




© PEPR NumPEx

C4P, a research network for the field of computing
Alfredo Buttari and Théo Mary, both NumPEx members, now lead the research network Computing: Paradigms, Parallelism, Performance, Precision (Groupement de recherche C4P).
The field of computing in computer science is undergoing rapid and disruptive changes, both at the conceptual and technological levels and in terms of the application needs of the academic and private sectors. In this context, the creation of the Research Group (GDR) Computing: Paradigms, Parallelism, Performance, Precision (C4P, pronounced [kap]) is motivated by the need to unite, structure and animate the French scientific research community in the field of computing in the broadest sense.
Computing, a field undergoing rapid transformation
The largest supercomputers have now reached exaflop scale (a speed of 1018 floating point operations per second). However, their extremely complex architecture is characterised by a very high level of parallelism and a high degree of heterogeneity in terms of computing units, memory and communication channels. Similarly, energy consumption has become a major concern, as the power consumption of these large computing infrastructures can reach several tens of megawatts.
Furthermore, while numerical simulation applications were the main use of computing centres for several decades, artificial intelligence, and more specifically machine learning, has recently come to occupy an increasing share of computing infrastructure resources. This discipline has experienced a veritable explosion in recent years, thanks in particular to the availability of computing resources that enable the training of very large models that now include billions of parameters.
Significant challenges:
In this context, marked by rapid technological changes that sometimes break with past approaches, scientific research in the field of computing is evolving. It faces significant challenges at several levels, from hardware and software to data management and numerical methods and algorithms. This can be summarised by the four ‘Ps’ in french:
- Paradigms: Design and develop emerging paradigms, such as quantum, neuromorphic, molecular, or in-memory computing, to overcome the limitations of von Neumann architecture and the end of Moore’s Law through more efficient, parallel, and frugal computing models.
- Parallelism: designing and developing algorithms, programming models and computing software capable of scaling up on modern computing infrastructures equipped with numerous heterogeneous computing units, memories and communication channels.
- Performance and energy: measuring, analysing and improving the performance of algorithms and computational software in terms of time, memory and energy consumption, taking into account the complexity and diversity of infrastructures and applications.
- Accuracy and robustness: measuring, controlling and guaranteeing the accuracy and robustness of algorithms and computational software in the face of errors, in a context where the use of low-precision arithmetic is increasingly widespread and failures are increasingly likely.
Read the original version on CNRS Informatics
© CNRS Sciences informatiques

The 2025 Exa-DoST general assembly
The 2025 Exa-DoST Annual Assembly took place from 5 to 7 November, 2025, bringing together 65 researchers and engineers from academia and industry to discuss the latest progress, prepare the milestones of the work packages, and welcome the latest recruits.
Exa-DoST (Data-oriented Software and Tools for the Exascale) is one of the five projects of the NumPEx program. Exa-DoST is addressing the major data challenges by proposing operational solutions co-designed and validated in French and European applications. This will allow filling the gap left by previous international projects to ensure that French and European needs are taken into account in the roadmaps for building the data-oriented Exascale software stack.
Finally, Exa-DoST was proud to welcome its new recruits, who rose brilliantly to the challenge of presenting scientific highlights in plenary sessions and via poster sessions!
Wednesday, 5 November 2025
- An introduction or refresher to NumPEx and Exa-DoST
by Gabriel Antoniu, Inria research scientist and Exa-DoST co-leader
and Julien Bigot, CEA research scientist and Exa-DoST co-leader - A few introductory words for everyone
by Gabriel Antoniu and Julien Bigot - First results and 2 scientific focuses for the workpackages:
- WP1 – I/O and data storage
by Francieli Boito, Inria research scientist and Exa-DoST WP leader
and François Tessier, Inria research scientist and Exa-DoST WP leader - WP2 – In situ data processing
by Yushan Wang, CEA research scientist and Exa-DoST WP leader
and Laurent Colombet, CEA research scientist and Exa-DoST WP leader - WP3 – ML-based data analytics
by Thomas Moreau, Inria research scientist and Exa-DoST WP leader
and Bruno Raffin, Inria research scientist and Exa-DoST WP leader - WP4:
by Virginie Grandgirard, CEA research scientist and Exa-DoST WP leader
and Damien Gratadour, Université Paris Cité professor and Exa-DoST WP leader
- WP1 – I/O and data storage
Thursday, 6 November 2025
-
Talk by François Mazen, Kitware
-
Talk by Xavier Delaruelle, TGCC
- Breakout sessions:
- Feedback on Gysela x WP1
Led by Virginie Grandgirard, Francieli Boito and François Tessier - Feedback on SKA x WP2
Led by Damien Gratadour and Yushan Wang, with the participation of Shan Mignot - Feedback on other apps (Coddex, Dyablo…) x WP3
Led by Laurent Colombet, Thomas Moreau and Brunon Raffin - Feedback on Gysela x WP2
Virginie Grandgirard, Yushan Wang and Laurent Colombet - Feedback on SKA x WP3
Led by Damien Gratadour, Thomas Moreau and Bruno Raffin - Feedback on other apps (Coddex, Dyablo…) x WP1
Led by Laurent Colombet, Francieli Boito and François Tessier
- Feedback on Gysela x WP1
Friday , 7 November 2025
-
How to approach modularity in librairy design within Exa-DoST?
by Julien Bigot - Breakout sessions:
- Feedback on Gysela x WP3
Led by Virginie Grandgirard, Thomas Moreau and Bruno Raffin - Feedback on SKA x WP1
Led by Damien Gratadour, Francieli Boito and François Tessier - Feeback on others apps (Coddex, Dyablo…) x WP2
Led by Laurent Colombet and Yushan Wang
- Feedback on Gysela x WP3
- Breakout sessions summary with all workpackages:
Attendees
- Mahamat Abdraman, Inria
- Jean-Thomas Acquaviva, DDN
- Gabriel Antoniu, Inria
- Julian AURIAC, CEA
- Rosa Maria Badia, BSC
- Alexis Bandet, Inria
- Iheb Becher, CNRS
- Mansour Benbakoura, Inria
- Andres Bermeo Marinelli, Inria
- Julien Bigot, CEA
- Jérôme Bobin, CEA
- François Bodin, Irisa
- Francieli Boito, Université de Bordeaux
- Robin Boezennec, Inria
- Etienne Bonnassieux, Université de Bordeaux
- Eric Boyer, Genci
- Valérie Brenner, CEA
- Silvina Caino-Lores, Inria
- Franck Cappello, Argonne National Laboratory, Online
- Pierre Cesar, Inria
- Jérôme Charousset, CEA
- Mathieu Cloirec, CINES
- Arnaud Collioud, Université de Bordeaux
- Laurent Colombet, CEA
- Marwane Dalal, Laboratoire d’Astrophysique de Bordeaux
- Ariel De Vora, CEA
- Xavier Delaruelle, CEA
- Arnaud Durocher, CEA
- Sofya Dymchenko, Inria
- Hugo Gaquere, Observatoire de Paris
- Virginie Grandgirard, CEA
- Damien Gratadour, Université Paris Cité
- Amina Guermouche, Inria
- Gabriel Hautreux, CINES, Online
- Hadrien Hendrikx, Inria
- Arthur Jaquard, Inria
- Théo Jolivel, Inria
- Sylvain Joube, CEA
- Ivan LUCAS, CEA
- Jakob Luettgau, Inria
- Martial Mancip, CEA
- Benoit Martin, CEA
- François Mazen, Kitware
- Yann Meurdesoif, CEA
- Shan Mignot, CNRS
- Thomas Moreau, Inria
- Jacques Morice, CEA
- Étienne Ndamlabin, Inria
- Guillaume Pallez, Inria
- Lucas Pernollet, CEA
- Abhishek Purandare, Inria
- Bruno Raffin, Inria
- Olivier Richard, Université Grenoble Alpes
- Kento Sato, Riken
- Hugo Strappazzon, Inria
- Frédéric Suter, Oak Ridge National Laboratory, Online
- François Tessier, Inria
- Samuel Thibault, Université de Bordeaux
- Luan Teylo, Inria
- Alix Tremodeux, ENS Lyon
- Méline Trochon, Inria
- Hippolyte Verninas, Inria
- Sunrise Wang, CNRS
- Yushan Wang, CEA
- Jad Yehya, Inria


©Martial Mancip / PEPR NumPEx
Exa-DI: the first mini-application resulting from co-development is now available!
Following the Exa-DI general meetings, working groups were formed to produce applications on four major themes. The first mini application on high-precision discretisation is now available.
Following the Exa-DI workshops, four working groups (WGs) were formed, bringing together all the players involved in co-design and co-development: Exa-DI’s Computational and Data Science (CDT) team, members of the various targeted NumPEx projects, and application demonstration teams. These groups focus on efficient discretisation, unstructured meshes, block-structured AMR, and AI applied to linear inverse problems at exascale, and are now actively moving forward.
Thanks to these WGs, the first shared mini-applications, representative of the technical challenges of exascale applications, are currently being developed. They integrate high value-added software components (libraries, frameworks, tools) provided by other NumPEx teams. In this context, the first mini-application on high-precision discretisation is now available, with others to follow soon.
A documentation hub, set up in early 2025, is gradually centralising tutorials and technical documents of general interest for NumPEx Exa-DI. It includes: the NumPEx software catalogue, webinars and training courses, documentation on co-design and CDT packaging, and much more.
Feel free to consult it to stay up to date on the tools and resources available.
Figure: Overview of Impact-HPC.
© PEPR NumPEx

Exa-DI: Facilitating the deployment of HPC applications with Package Managers
Exa-DI is proud to present its series of training courses for users of package managers, designed to optimise their user experience.
Deploying and porting applications on supercomputers remains a complex and time-consuming task. NumPEx encourages users to leverage package managers, allowing for precise and direct control of their software stack, with a particular focus on Guix and Spack.
A series of training courses and support events has been organised to assist users:
• Tutorial: Introduction to Guix – October 2025
• Tutorial @ Compass25: Guix-deploy – June 2025
• Coding session: Publishing packages on Guix-Science – May 2025
• Tutorial: Spack for beginners (online) – April 2025
• Tutorial: Using Guix and Spack for deploying applications on supercomputers – February 2025
Switching to new deployment methods takes time. NumPEx supports users by offering training, support, software packaging, tool improvements, and partnerships with computing centres to optimise the user experience.
For more information: https://numpex-pc5.gitlabpages.inria.fr/tutorials/webinar/index.html
Photo credit: Mohammad Rahmani / Unsplash

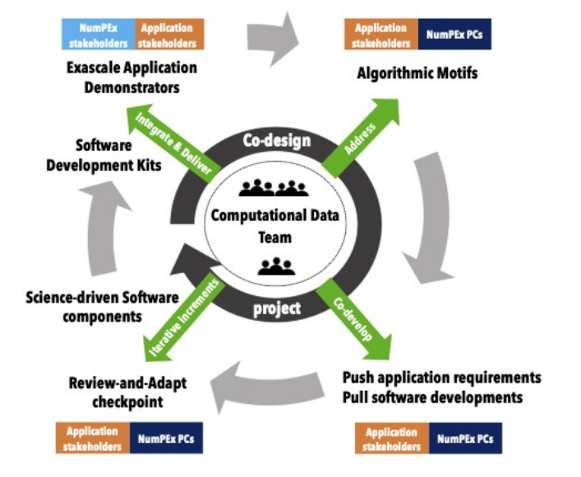
Exa-DI: the co-design and co-development in NumPEx is moving forward
The implementation of the co-design and co-development process within NumPEx is one of Exa-DI’s objectives for the production of augmented and productive software. To this end, Exa-DI has organised three working groups open to all NumPEx members.
The Exa-DI project is responsible for implementing the co-design and co-development process within NumPEx, with the aim of producing augmented and productive exascale software that is science-driven. In this context, Exa-DI has already organised three workshops: one on “Efficient discretisation for exascale EDPs”, another on “Block-structured AMR at exascale” and a third on “Artificial intelligence for exascale HPC”. These two-day in-person workshops brought together Exa-DI members, members of other NumPEx projects, teams demonstrating applications from various sectors of research and industry, and experts.
Discussions focused on:
-
- Challenges related to the co-design and co-development process
- Key issues
- The most pressing issues for collective development and strengthening links between NumPEx and applications
- Initiatives promoting the sustainability of exascale software and performance portability.
A very interesting and stimulating result was the establishment of working groups focused on a set of shared and well-specified mini-applications representing the cross-cutting computational and communication patterns identified. Several application teams have expressed interest in participating in these groups. To date, four working groups are actively engaged in the co-design and co-development of mini-applications, with a view to integrating and evaluating the logical sets of software components developed in the NumPEx projects.
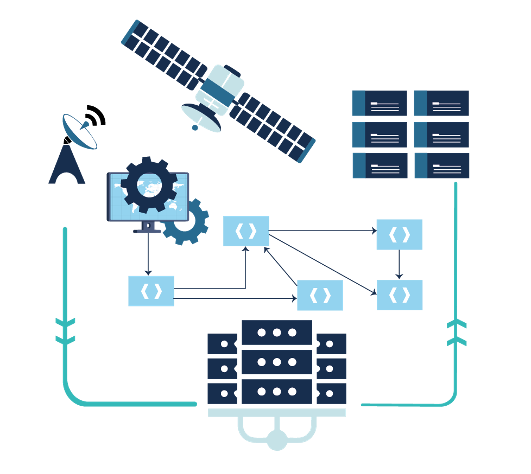
Strategy for the interoperability of digital scientific infrastructures
The evolution of data volumes and computing capabilities is reshaping the scientific digital landscape. To fully leverage this potential, NumPEx and its partners are developing an open interoperability strategy connecting major instruments, data centers, and computing infrastructures.
Driven by data produced by large instruments (telescopes, satellites, etc.) and artificial intelligence, the digital scientific landscape is undergoing a profound transformation, fuelled by rapid advances in computing, storage and communication capabilities. The scientific potential of this inherently multidisciplinary revolution lies in the implementation of hybrid computing and processing chains, increasingly integrating HPC infrastructures, data centres and large instruments.
Anticipating the arrival of the Alice Recoque exascale machine, NumPEx’s partners and collaborators (SKA-France, MesoCloud, PEPR NumPEx, Data Terra, Climeri, TGCC, Idris, Genci) have decided to coordinate their efforts to propose interoperability solutions that will enable the deployment of processing chains that fully exploit all research infrastructures.
The aim of the work is to define an open strategy for implementing interoperability solutions, in conjunction with large scientific instruments, in order to facilitate data analysis and enhance the reproducibility of results.
Figure: Overview of Impact-HPC.
© PEPR NumPEx