


La réunion annuelle 2026 de l'Exa-DI
La réunion annuelle 2026 du projet Exa-DI (Développement et Intégration) du PEPR NumPEx s’est tenue les 24 et25 février à l’Espace Trinité, à Paris.
Cette réunion en face à face a rassemblé pendant une journée l’équipe complète d’Exa-DI – les membres de chaque Work Package (WPs), le gestionnaire de programme du CDT, les membres du CDT, les responsables des groupes de travail (WGs) de co-conception/co-développement qui sont membres des équipes de démonstrateurs d’applications (ADs ), les membres des autres projets NumPEx du (Exa-MA, Exa-SofT, Exa-DoST et Exa-AToW), ainsi que des représentants des centres de calcul nationaux (IDRIS, TGCC, CINES) et régionaux (GriCAD,) et des experts.
Cette réunion a d’abord été l’occasion de créer une dynamique entre toutes les parties prenantes impliquées dans les processus de co-conception/co-développement et ensuite de renforcerleur alignement. C’est l’un des principaux objectifs des sessions Backlog au cours desquelles chaque groupe de travail de co-conception/co-développement a présenté sa feuille de route pour les 2-3 mois à venir afin d’établir, de coordonner et d’organiser les activités d’ingénierie de l’équipe de développement du CDT. Compte tenu de l’importance et de la nature transversale du sujet dans l’ensemble du NumPEx, une présentation sur « la programmation basée sur les tâches et ses applications » a été faite par un expert du projet Exa-SofT. La session « Software packaging and deployment » organisée avec la participation d’un centre de calcul régional (GriCAD) et de tous les centres de calcul nationaux (TGCC, IDRIS et CINES) offre l’opportunité de discuter des solutions de packaging (par exemple, modules, Spack, Guix) dans le but d’aider les développeurs de code à porter et à déployer des applications sur différentes architectures, et en particulier sur les principales architectures exascales. La session CDT a fourni une vue d’ensemble des activités d’ingénierie actuelles de l’équipe de développement CDT à travers quatre présentations, à savoir Infrastructure pour l’analyse comparative, Déploiement basé sur Guix et intégration unifiée de Kokkos, Opérateurs d’éléments spectraux à haute performance sur GPU et Analyse comparative des algorithmes de résolution de problèmes inverses à grande échelle avec Benchopt, qui ont été suivies d’une discussion générale. Enfin, à la lumière du récent atelier organisé par GENCI à la suite de la passation de marché d’Alice Recoque (17-19 février 2026), où les collaborations entre NumPEx, Bull et AMD ont été discutées, une session spécifique sur les collaborations possibles Exa-DI/AMD/Bull a été organisée pour, d’une part, donner un retour sur l’atelier Bull/AMD et, d’autre part, discuter des actions à mettre en œuvre pour identifier et démarrer des collaborations avec AMD et Bull.
L’un des principaux objectifs de cette réunion était de réfléchir ensemble aux modèles de collaboration qui soutiennent la montée en puissance du projet Exa-DI et leur mise en œuvre par le biais des structures de co-conception/co-développement mises en place dans Exa-DI : le CDT, les groupes de travail de co-conception/co-développement, les groupes de travail, etc. Un point clé a été de suivre et de vérifier que l’articulation et la coordination de ces différentes structures étaient effectuées correctement et permettaient d’assurer le succès du processus de co-conception/co-développement. Ceci est essentiel pour préparer le portage des applications vers les architectures exascales et en particulier vers la prochaine installation exascale européenne qui sera installée au TGCC, Alice Recoque et ouverte aux utilisateurs d’ici la fin de 2027.
Cette réunion annuelle du projet est cruciale pour contrôler la bonne conduite du projet et assurer la bonne coordination des activités d’ingénierie et d’emballage au sein du CDT en collaboration avec toutes les parties prenantes, un point clé du processus de co-conception et de co-développement.
Les points forts des différentes composantes du processus de co-conception/co-développement, tels que la feuille de route des groupes de travail sur la co-conception/le co-développement, les activités d’ingénierie de l’équipe de développement du CDT, lesactivités de conditionnement et de déploiement du logiciel de l’équipe d’habilitation du CDT, ont permis de démontrer l’importance primordiale de toutes ces activités différentes pour mettre en œuvre et réaliser le processus de co-conception et de co-développement, ainsi que des collaborations dans les activités quotidiennes de recherche et d’ingénierie. Les discussions avec les centres de calcul nationaux et régionaux ont permis de clarifier les différentes solutions actuelles et futures pour l’emballage et le déploiement de logiciels dans les centres de calcul régionaux et nationaux et ont mis en évidence ce qui devra être mis en œuvre compte tenu de l’hétérogénéité des architectures futures. En outre, tous les participants à cette session ont convenu de se rencontrer à nouveau à l’avenir afin de se tenir mutuellement informés des développements et d’en discuter ensemble. Dans l’ensemble, les discussions ont été très fructueuses et ont montré qu’il existe une forte motivation et un grand intérêt pour le renforcement des collaborations entre toutes les parties prenantes impliquées dans les processus de co-conception/co-développement, et pour éviter autant que possible les silos et le travail en vase clos.
Mardi 24 février 2026
- Introduction
par Valérie Brenner, chercheur au CEA - Session Backlog
par Jérôme Charousset, ingénieur au CEA- Feuille de route Groupe de travail (GT) 1
par Henri Calandra, Expert méthodes numériques et calcul haute performance à TotalEnergies - Roadmap WG2
par Julien Vanharen, chercheur à l’Inria - Roadmap WG3
Maxime Delorme, chercheur au CEA - Roadmap WG4
Thomas Moreau, chercheur à l’Inria
- Feuille de route Groupe de travail (GT) 1
- Programmation par tâches et ses applications
par Samuel Thibault, professeur à l’Université de Bordeaux - Session sur le packaging et le déploiement de logiciels
par Benoît Martin, chercheur à l’Université de la Sorbonne- Empaquetage et déploiement de logiciels dans Exa-DI
par Benoît Martin, chercheur à l’Université de la Sorbonne
et Bruno Raffin, chercheur à l’Inria - Le packaging et le déploiement de logiciels à GriCAD
par Pierre-Antoine Bouttier, ingénieur CNRS - Packaging et déploiement de logiciels au TGCC
par Xavier Delaruelle, responsable CEA et Laurent Nguyen, ingénieur CEA - Le packaging et le déploiement de logiciels à l’IDRIS
par Remi Lacroix, ingénieur CNRS - Packaging et déploiement de logiciels au CINES
par Gabriel Hautreux, expert HPC au CINES
- Empaquetage et déploiement de logiciels dans Exa-DI
Mercredi 25 février 2026
- Session CDT
par Félix Kpadonou, chercheur au CEA- Infrastructure pour le benchmarking
par Jérôme Charousset, ingénieur au CEA - Déploiement sur Guix et intégration unifiée de Kokkos
par Aurélien Dauteuil, ingénieur CEA - Opérateurs d’éléments spectraux haute performance sur GPU
par Alexandre Roger, CNRS - Benchmarking Large Scale Inverse Problems Resolution Algorithms with Benchopt
par Benoit Malézieux, chercheur au CNRS
- Infrastructure pour le benchmarking
- Session sur les collaborations AMD
par Jérôme Bobin, chercheur au CEA
Participantes et participants
- Juliette Antonczack, Exa-MA, Université de Strasbourg
- Alexis Badel, Inria
- Rémi Baron, Exa-DI, CEA
- Baptiste Besnard, CNRS
- Julien Bigot, Exa-DI, Inria
- Jérôme Bobin, Exa-DI, CEA
- Pierre-Antoine Bouttier, CNRS
- Thomas Bouvier, Exa-DI, CEA
- Eric Boyer, Genci
- Valérie Brenner, Exa-DI, CEA
- Henri Calandra, AD, TotalEnergies
- Ansar Calloo, Exa-MA, CEA
- Mathieu Certenais, Exa-AToW, Université de Rennes
- Aurélien Citrain, Inria
- Jérôme Charousset, Exa-DI, CEA
- Javier Cladellas, Exa-MA, Université de Strasbourg
- Ludovic Courtes, Exa-DI, Inria
- Aurélien Dauteuil, Exa-DI, CEA
- Xavier Delaruelle, CEA
- Romain Denelle, EDF
- Maxime Delorme, AD, CEA
- Etienne Decossin, EDF
- Triem Phan Dinh, Exa-DI, CNRS
- Romain Garbage, Exa-DI, Inria
- Damien Gradatour, Exa-DoST, CNRS
- Virginie Grangirard, Exa-DoST, CEA
- Loïc Guoarin, Exa-MA, École Polytechnique
- Gabriel Hautreux, Université de Montpellier
- Skander Khiari, Exa-DI, CEA
- Chai Koren, EDF
- Félix Kpadonou, Exa-DI, CEA
- Rémi Lacroix, CNRS
- Pierre-François Lavallée, CNRS
- Guillaume Lechantre, Genci
- Benoît Malézieux, Exa-DI, CNRS
- Benoît Martin, Exa-DI, CEA
- Marc Antoine Miville-Deschênes, CNRS
- Thomas Moreau, GT IA, CEA
- Laurent Nguyen, CEA
- Augustin Parret-Freaud, Safran Tech
- Bruno Raffin, Exa-DI, Inria
- Alexandre Roger, Exa-DI, CNRS
- Pascal Tremblin, CEA
- Samuel Thibaut, Exa-SofT, Inria
- Jean-Pierre Vilotte, Exa-DI, CNRS
- Julien Vanharen, AD, Inria





PEPR NumPEx
Trans Numériques 2026
Le PEPR NumPEx était fier de participer à la première édition des Trans Numériques ! Treize PEPR se sont réunis du 2 au 5 février au Couvent des Jacobins à Rennes pour partager les avancées scientifiques et les défis liés à la performance, la sécurité, la frugalité et l’impact sociétal du continuum numérique.
Cet événement a été l’occasion pour NumPEx de se réunir pour réfléchir aux prochaines étapes du programme, en particulier sur trois thèmes majeurs : La convergence IA et HPC, l’écosystème logiciel et le continuum numérique. En même temps, cet événement a permis d’échanger des idées avec d’autres PEPR et de partager des projets inter-PEPR avec la communauté numérique.
Enfin, nous sommes très fiers de Méline Trochon et Théo Jolivel, doctorants au NumPEx, qui ont représenté le NumPEx dans la vidéo de l’ANR et ont partagé leur regard neuf sur l’événement !
Programme NumPEx
Mardi 3 février 2026
- Introduction aux sessions NumPEx uniquement
- Convergence IA et HPC
- Ecosystème logiciel
- Continuum numérique
Mercredi 4 février 2026
- Convergence IA et HPC – atelier
- Ecosystème logiciel – atelier
- Continuum numérique – atelier
Jeudi 5 février 2026
- Restitution de l’atelier
Thomas Crabot
Le film ANR de l'événement

La réunion annuelle 2026 d'Exa-MA
L’assemblée annuelle d’Exa-MA 2026, qui s’est tenue aux Arts et Métiers ParisTech (Aix-en-Provence) du 19 au 21 janvier 2026, a souligné le rôle central du projet dans l’initiative française NumPEx. Il s’est concentré sur la préparation de la pile logicielle pour le supercalculateur exascale « Alice Recoque ».
Exa-MA vise à révolutionner les méthodes et algorithmes pour l’échelle exascale : discrétisation, résolution, apprentissage et réduction d’ordre, problème inverse, optimisation et incertitudes. Nous contribuons à la pile logicielle des futurs ordinateurs européens.
La troisième assemblée générale d’Exa-MA a mis en lumière le rôle central du projet dans l’initiative française NumPEx, en préparant la pile logicielle pour le supercalculateur exascale « Alice Recoque ». Les principales discussions ont porté sur les priorités pour 2026 : la portabilité des GPU, la convergence HPC pilotée par l’IA et les opérateurs neuronaux en temps réel, avec des applications dans les domaines de l’énergie de fusion, de la modélisation du climat et de l’aéronautique. L’assemblée a mis l’accent sur la fourniture de solutions souveraines, ouvertes et reproductibles, tout en relevant des défis tels que la fiabilité de l’IA dans le HPC et l’accélération du GPU. En développant la formation et les démonstrateurs, Exa-MA renforce son « modèle français » d’innovation collaborative, jetant un pont entre l’IA et le HPC pour un impact scientifique et sociétal mesurable.
Lundi 19 janvier 2026
- Présentation générale de NumPEx et Exa-MA
- Présentations des groupes de travail : progrès accomplis + points forts scientifiques + prochaines étapes
Mercredi 21 2026
- Présentation de Sage-HPC (AI for HPC)
- Présentation de Daimos (HPC for AI)
- Retour d’information des groupes de travail (réunions internes aux groupes de travail + sessions en petits groupes avec les cadres) :
- WP1 – Discrétisation
- WP2 – Ordre du modèle, substitut, méthodes scientifiques de ML
- WP3 – Solveur pour l’algèbre linéaire et la multiphysique
- WP4 – Combinaison de données et de modèles, problèmes inverses
- WP5 – Optimisation
- WP6 – Quantification de l’incertitude
- WP7 – Showroom, benchmarking et coordination de la co-conception
Participantes et participants
- Emmanuel Agullo, Inria
- Pierre Alliez, Inria
- Amaury Bélières Frendo, Unistra
- Ani Anciaux Sedrakian, IFPEN
- Brieuc Antoine dit Urban, Inria
- Juliette Antonczak, Unistra
- Mark Asch, Université de Picardie
- Hassan Ballout, Unistra
- Hélène Barucq, Inria
- Jérôme Bobin, CEA
- Jed Brown, Université du Colorado
- Filippo Brunelli, Inria
- Ansar Calloo, CEA
- Xinye Chen, Sorbonne Université
- Javier Cladellas, Unistra
- Susanne Claus, ONERA
- Ariel De Vora, CEA
- Mohamed Doumbouya, Inria
- Pierre Dubois, CEA
- Mahmoud El khadiri, Inria
- Erik Fabrizzi, Sorbonne Université
- Vincent Faucher, CEA
- Emmanuel Franck, Inria
- Josselin Garnier, Ecole Polytechnique
- Clément Gauchy, CEA
- Christophe Geuzaine, Université de Liège
- Laetitia Giraldi, Inria
- Loic Gouarin, Ecole Polytechnique
- Arthur Gouinguenet, Inria
- Virginie Grandgirard, CEA
- Julien Herrmann, Inria
- Alexandre Hoffmann, Ecole Polytechnique
- Remy Hosseinkhan, Ecole Polytechnique
- Daria Hrebenshchykova, Inria
- Bertrand Iooss, EDF
- Vincent Italiano, Unistra
- Utpal Kiran, CEA
- Félix Kpadonou, CEA
- Philipp Krah, CEA
- Stéphane Lanteri, Inria
- Romain Le Tellier, CEA
- Benoît Malézieux, CEA
- Gilles Marait, Inria
- Jean-Baptiste Mascary, ANR
- Lois McInnes, Laboratoire national d’Argonne
- Victor Michel-Dansac, Inria
- Mahamat Hamdan Nassouradine, CEA
- Frédéric Nataf, Sorbonne Université
- Laurent Navoret, Unistra
- Lars Nerger, Institut Alfred Wegener
- Augustin Parret-Fréaud, Safran
- Lucas Pernollet, CEA
- Raphaël Prat, CEA
- Christophe Prud’homme, Unistra
- Isabelle Ramière, CEA
- Yves Robert, ENS
- Mael Rouxel-Labbe, Geometry Factory
- Gianluigi Rozza, SISSA
- Eric Savin, ONERA
- Lukas Spies, Inria
- Alexandre Tabouret, Sorbonne Université
- El-ghazali Talbi, Université de Lille
- Tom Caruso, Inria
- Sébastien Tordeux, Inria
- Arthur Vidard, Inria
- Jean-Pierre Vilotte, CNRS




PEPR NumPEx

C4P, un groupement de recherche pour le domaine du calcul
Alfredo Buttari et Théo Mary, tous deux membres de NumPEx, dirigent désormais le Groupement de recherche (GDR) Calcul : paradigmes, parallélisme, performance, précision (C4P, prononcer [kap]).
Le domaine des sciences informatiques est en évolution constante, tant au niveau conceptuel et technologique qu’au niveau qu’aux applications dans des secteurs clés. Dans ce contexte, la GDR C4P permettra de fédérer, structurer et animer la communauté française autour du calcul intégrée dans le continuum numérique.
Lire l’article complet sur CNRS Sciences informatiques
Image : © CNRS Sciences informatiques

La première assemblée générale de YoungPEx
Le comité YoungPEx est une initiative de NumPEx visant à rassembler de jeunes chercheurs pour discuter de l’avenir du calcul à haute performance et de la science ouverte. Cet événement a été une première étape importante pour dynamiser le comité et parler de sujets qui seront essentiels à l’avenir. Plusieurs ateliers ont été organisés :
- Un atelier sur l’impact environnemental du HPC
animé par Georges Da Costa, professeur à l’Université de Toulouse et membre d’Exa-SoFt - Une assemblée générale pour discuter des actions à venir du comité YoungPEx et du renouvellement des membres organisateurs.
- Un atelier sur le thème des inégalités sociales et de genre
Mercredi 12 novembre 2025
Cette première journée d’atelier a été animée par Georges Da Costa, professeur à l’Université de Toulouse et membre d’Exa-SoFt.
- L’informatique durable ?
- Avenir du calcul haute performance : prochaines étapes pour le calcul haute performance ?
- Introduction à la grille 5000
Jeudi 13 novembre 2025
Cette deuxième journée a été l’occasion d’approfondir les thèmes de la première journée.
L’après-midi a été consacrée à rassembler les membres de la communauté, à échanger sur leurs travaux par le biais de nombreuses activités :
- Antithèse: Quatre présentations ont été préparées avant la journée, et quatre participants se sont portés volontaires pour la présenter, en découvrant les diapositives 5 minutes avant la présentation.
- Start-up nation : les participants ont été divisés en quatre groupes et ont dû créer une présentation d’une start-up ou d’un projet de recherche qui susciterait l’intérêt de tous les membres.
- Retour d’information sur l’atelier et émergence d’idées
- Idées pour les actions futures de YoungPEx.
Vendredi 14 novembre 2025
Le dernier jour, le thème principal était l’équité et l’égalité dans les sciences. Trois sessions différentes ont été organisées :
- le Monopoly des inégalités, un jeu inspiré du célèbre Monopoly, destiné à mettre en évidence le fait que tout le monde n’a pas les mêmes chances de réussir, animé par Yasmina Asso de l’Observatoire des inégalités;
- Présentation par Julie Lesthelle, de l’Université de Bordeaux, des résultats de son mémoire de master intitulé Les études en licence de mathématiques sous le prisme du genre : Construction d’un environnement masculin et expériences des étudiantes en situation minoritaire.
- Une table ronde sur le concept de leaking pipeline, avec l’intervention d’Elsa Cazelles (Chargée de Recherche à l’IRIT), Sylvie Chambon (Professeure des Universités à ENSEEIHT), Julie Lesthelle (étudiante à l’Université de Bordeaux), Lucie Baudouin (Directrice de Recherche au LASS) et Aline Roc (ingénieure de recherche au CATIE).
Ces sessions ont permis de faire le point sur la question de l’égalité et de l’équité et de formuler des recommandations et des signaux d’alerte pour identifier ou prévenir d’autres inégalités au sein de la communauté NumPEx.
Comité d'organisation
- Thomas Saigre, postdoctorant Inria à l’IRMA et membre d’Exa-MA
- Karmijn Hoogveld, doctorant CNRS à l’IRIT et membre d’Exa-SofT
- Méline Trochon, doctorante Inria au LaBRI et à Exa-DoST
- Mathis Certenais, doctorant de l’Université de Rennes à l’Irisa et membre d’Exa-AtoW
- Romain Garbage, ingénieur Inria et membre d’Exa-DI
Les organisateurs tiennent à remercier tous les participants à cet événement, ainsi que Georges Da Costa, Yasmina Asso, Julie Lesthelle, Elsa Cazelles, Sylvie Chambon, Lucie Beaudouin et Aline Roc pour leur temps et leur participation aux différentes activités !



Karmijn Hoogveld, Alfredo Buttari

L'assemblée générale d'Exa-DoST 2025
L’assemblée annuelle d’Exa-DoST 2025 s’est tenue du 5 au 7 novembre 2025, réunissant 65 chercheurs et ingénieurs du monde universitaire et de l’industrie pour discuter des dernières avancées, préparer les jalons des work packages, et accueillir les dernières recrues.
Exa-DoST (Data-oriented Software and Tools for the Exascale) est l’un des cinq projets du programme NumPEx. Exa-DoST aborde les grands défis liés aux données en proposant des solutions opérationnelles co-conçues et validées dans des applications françaises et européennes. Cela permettra de combler le vide laissé par les projets internationaux précédents afin de garantir que les besoins français et européens soient pris en compte dans les feuilles de route pour la construction de la pile logicielle Exascale axée sur les données.
Enfin, Exa-DoST a été fière d’accueillir ses nouvelles recrues, qui ont brillamment relevé le défi de présenter des faits scientifiques marquants en sessions plénières et par le biais de sessions de posters !
Mercredi 5 novembre 2025
- Une introduction ou un rafraîchissement à NumPEx et Exa-DoST
par Gabriel Antoniu, chercheur Inria et co-leader Exa-DoST
et Julien Bigot, chercheur CEA et co-leader Exa-DoST - Quelques mots d’introduction pour tous
par Gabriel Antoniu et Julien Bigot - Premiers résultats et 2 axes scientifiques pour les lots de travail :
- WP1 – E/S et stockage de données
par Francieli Boito, chercheur à l’Inria et responsable du WP Exa-DoST
et François Tessier, chercheur à l’Inria et responsable du WP Exa-DoST - WP2 – Traitement des données in situ
par Yushan Wang, chercheur au CEA et responsable du WP Exa-DoST
et Laurent Colombet, chercheur au CEA et responsable du WP Exa-DoST - WP3 – ML-based data analytics
par Thomas Moreau, chercheur à l’Inria et responsable du WP Exa-DoST
et Bruno Raffin, chercheur à l’Inria et responsable du WP Exa-DoST - WP4 :
par Virginie Grandgirard, chercheur au CEA et responsable du WP Exa-DoST
et Damien Gratadour, professeur à l’Université Paris Cité et responsable du WP Exa-DoST.
- WP1 – E/S et stockage de données
Jeudi 6 novembre 2025
-
Intervention de François Mazen, Kitware
-
Exposé de Xavier Delaruelle, TGCC
- Séances en petits groupes :
- Retour d’expérience sur Gysela x WP1
Dirigé par Virginie Grandgirard, Francieli Boito et François Tessier - Feedback sur SKA x WP2
Dirigé par Damien Gratadour et Yushan Wang, avec la participation de Shan Mignot - Feedback sur d’autres applications (Coddex, Dyablo…) x WP3
Dirigé par Laurent Colombet, Thomas Moreau et Brunon Raffin - Retour d’expérience sur Gysela x WP2
Virginie Grandgirard, Yushan Wang et Laurent Colombet - Feedback sur SKA x WP3
Dirigé par Damien Gratadour, Thomas Moreau et Bruno Raffin - Retour d’information sur d’autres applications (Coddex, Dyablo…) x WP1
Dirigé par Laurent Colombet, Francieli Boito et François Tessier
- Retour d’expérience sur Gysela x WP1
Vendredi 7 novembre 2025
-
Comment aborder la modularité dans la conception des bibliothèques au sein d’Exa-DoST ?
par Julien Bigot - Séances en petits groupes :
- Feedback sur Gysela x WP3
Dirigé par Virginie Grandgirard, Thomas Moreau et Bruno Raffin - Retour d’information sur SKA x WP1
Dirigé par Damien Gratadour, Francieli Boito et François Tessier - Feeback sur d’autres applications (Coddex, Dyablo…) x WP2
Dirigé par Laurent Colombet et Yushan Wang
- Feedback sur Gysela x WP3
- Résumé des sessions en petits groupes avec tous les lots de travail :
Participantes et participants
- Mahamat Abdraman, Inria
- Jean-Thomas Acquaviva, DDN
- Gabriel Antoniu, Inria
- Julian AURIAC, CEA
- Rosa Maria Badia, BSC
- Alexis Bandet, Inria
- Iheb Becher, CNRS
- Mansour Benbakoura, Inria
- Andres Bermeo Marinelli, Inria
- Julien Bigot, CEA
- Jérôme Bobin, CEA
- François Bodin, Irisa
- Francieli Boito, Université de Bordeaux
- Robin Boezennec, Inria
- Etienne Bonnassieux, Université de Bordeaux
- Eric Boyer, Genci
- Valérie Brenner, CEA
- Silvina Caino-Lores, Inria
- Franck Cappello, Laboratoire national d’Argonne, en ligne
- Pierre Cesar, Inria
- Jérôme Charousset, CEA
- Mathieu Cloirec, CINES
- Arnaud Collioud, Université de Bordeaux
- Laurent Colombet, CEA
- Marwane Dalal, Laboratoire d’Astrophysique de Bordeaux
- Ariel De Vora, CEA
- Xavier Delaruelle, CEA
- Arnaud Durocher, CEA
- Sofya Dymchenko, Inria
- Hugo Gaquere, Observatoire de Paris
- Virginie Grandgirard, CEA
- Damien Gratadour, Université Paris Cité
- Amina Guermouche, Inria
- Gabriel Hautreux, CINES, en ligne
- Hadrien Hendrikx, Inria
- Arthur Jaquard, Inria
- Théo Jolivel, Inria
- Sylvain Joube, CEA
- Ivan LUCAS, CEA
- Jakob Luettgau, Inria
- Martial Mancip, CEA
- Benoit Martin, CEA
- François Mazen, Kitware
- Yann Meurdesoif, CEA
- Shan Mignot, CNRS
- Thomas Moreau, Inria
- Jacques Morice, CEA
- Étienne Ndamlabin, Inria
- Guillaume Pallez, Inria
- Lucas Pernollet, CEA
- Abhishek Purandare, Inria
- Bruno Raffin, Inria
- Olivier Richard, Université Grenoble Alpes
- Kento Sato, Riken
- Hugo Strappazzon, Inria
- Frédéric Suter, Laboratoire national d’Oak Ridge, en ligne
- François Tessier, Inria
- Samuel Thibault, Université de Bordeaux
- Luan Teylo, Inria
- Alix Tremodeux, ENS Lyon
- Méline Trochon, Inria
- Hippolyte Verninas, Inria
- Sunrise Wang, CNRS
- Yushan Wang, CEA
- Jad Yehya, Inria


©Martial Mancip / PEPR NumPEx
Exa-DI : la première mini-application issue du co-développement est désormais disponible !
Suite aux réunions générales d’Exa-DI, des groupes de travail ont été constitués pour produire des applications sur quatre thèmes majeurs. La première mini-application sur la discrétisation de haute précision est maintenant disponible.
Suite aux ateliers Exa-DI, quatre groupes de travail (GT) ont été constitués, réunissant tous les acteurs impliqués dans la co-conception et le co-développement : l’équipe Computational and Data Science (CDT) d’Exa-DI, les membres des différents projets NumPEx ciblés et les équipes de démonstration d’applications. Ces groupes se concentrent sur la discrétisation efficace, les maillages non structurés, l’AMR structurée par blocs et l’IA appliquée aux problèmes inverses linéaires à l’échelle exascale.
Grâce à ces groupes de travail, les premières mini-applications partagées, représentatives des défis techniques des applications exascales, sont en cours de développement. Elles intègrent des composants logiciels à forte valeur ajoutée (bibliothèques, frameworks, outils) fournis par d’autres équipes NumPEx. Dans ce contexte, la première mini-application sur la discrétisation de haute précision est maintenant disponible, et d’autres suivront bientôt.
Un hub documentaire, mis en place début 2025, centralise progressivement les tutoriels et documents techniques d’intérêt général pour NumPEx Exa-DI. Il comprend : le catalogue du logiciel NumPEx, des webinaires et des formations, de la documentation sur la co-conception et le packaging CDT, et bien d’autres choses encore.
N’hésitez pas à le consulter pour vous tenir au courant des outils et des ressources disponibles.
Figure : Vue d’ensemble d’Impact-HPC.
PEPR NumPEx

Exa-DI : Faciliter le déploiement d'applications HPC avec les Package Managers
Exa-DI est fier de présenter sa série de formations destinées aux utilisateurs de package managers, conçues pour optimiser leur expérience d’utilisation.
Le déploiement et le portage d’applications sur des supercalculateurs reste une tâche complexe et fastidieuse. NumPEx encourage les utilisateurs à utiliser des gestionnaires de paquets, permettant un contrôle précis et direct de leur pile logicielle, avec un accent particulier sur Guix et Spack.
Une série de cours de formation et d’événements de soutien a été organisée pour aider les utilisateurs :
– Tutoriel : Introduction à Guix – Octobre 2025
– Tutoriel @ Compass25 : Guix-deploy – Juin 2025
– Coding session : Publication de paquets sur Guix-Science – Mai 2025
– Tutoriel : Spack pour les débutants (en ligne) – Avril 2025
– Tutoriel : Utiliser Guix et Spack pour déployer des applications sur des supercalculateurs – Février 2025
Le passage à de nouvelles méthodes de déploiement prend du temps. NumPEx soutient les utilisateurs en proposant des formations, une assistance, un packaging logiciel, des améliorations d’outils et des partenariats avec des centres de calcul pour optimiser l’expérience de l’utilisateur.
Pour plus d’informations : https://numpex-pc5.gitlabpages.inria.fr/tutorials/webinar/index.html
Crédit photo : Mohammad Rahmani / Unsplash

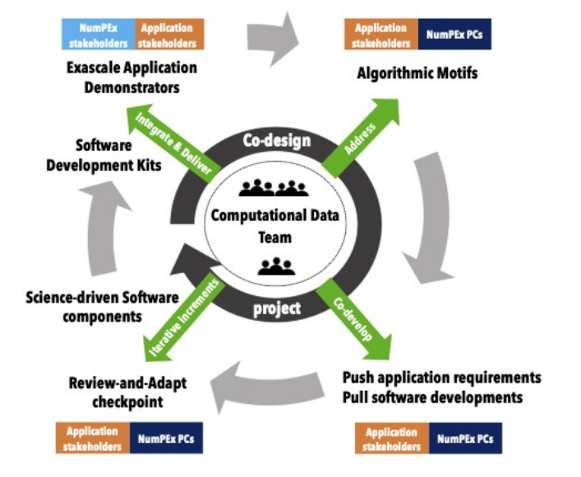
Exa-DI : la co-conception et le co-développement dans NumPEx progressent
La mise en œuvre du processus de co-conception et co-développement au sein de NumPEx est un des objectifs d’Exa-DI, pour la production de logiciel augmenté et productif. Pour cela, Exa-DI a organisé trois groupes de travail ouvert à tous les membres de NumPEx.
Le projet Exa-DI est chargé de mettre en œuvre le processus de co-conception et de co-développement au sein de NumPEx, dans le but de produire des logiciels exascales augmentés et productifs, orientés vers la science. Dans ce contexte, Exa-DI a déjà organisé trois ateliers: un sur la discrétisation efficace pour les EDP exascales, un autre sur l’AMR structuré par blocs à l’échelle exascale et un troisième sur l’intelligence artificielle pour le HPC exascale. Ces ateliers de deux jours en personne ont rassemblé des membres d’Exa-DI, des membres d’autres projets NumPEx, des équipes présentant des applications issues de divers secteurs de la recherche et de l’industrie, ainsi que des experts.
Les discussions ont porté sur les points suivants
-
- Défis liés au processus de co-conception et de co-développement
- Questions clés
- Les questions les plus urgentes pour le développement collectif et le renforcement des liens entre NumPEx et les applications
- Initiatives visant à promouvoir la durabilité des logiciels exascales et la portabilité des performances.
Un résultat très intéressant et stimulant a été la création de groupes de travail axés sur un ensemble de mini-applications partagées et bien spécifiées représentant les modèles transversaux de calcul et de communication identifiés. Plusieurs équipes d’application ont exprimé leur intérêt à participer à ces groupes. À ce jour, quatre groupes de travail sont activement engagés dans la co-conception et le co-développement de mini-applications, en vue d’intégrer et d’évaluer les ensembles logiques de composants logiciels développés dans les projets NumPEx.
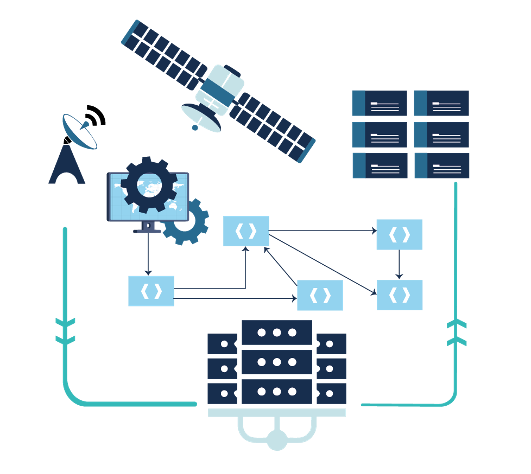
Stratégie pour l’interopérabilité des infrastructures numériques scientifiques
L’évolution des volumes de données et des capacités de calcul est en train de remodeler le paysage numérique scientifique. Pour exploiter pleinement ce potentiel, NumPEx et ses partenaires développent une stratégie d’interopérabilité ouverte reliant les principaux instruments, centres de données et infrastructures de calcul.
Porté par la production des données issues des grands instruments (télescopes, satellites, etc.) et de l’intelligence artificielle, le paysage numérique scientifique connaît une transformation profonde, alimentée par l’évolution rapide des capacités de calcul, de stockage et de communication. Le potentiel scientifique de cette révolution, intrinsèquement multidisciplinaire, repose sur la mise en œuvre de chaînes hybrides de calcul et de traitement, intégrant de manière croissante les infrastructures HPC, les centres de données et les grands instruments.
Anticipant l’arrivée de la machine Exascale Alice Recoque, les partenaires et collaborations de NumPEx (SKA-France, MesoCloud, PEPR Numpex, Data Terra, Climeri, TGCC, Idris, Genci) ont décidé de coordonner leurs efforts afin de proposer des solutions d’interopérabilité, permettant le déploiement de chaînes de traitement exploitant pleinement l’ensemble des infrastructures de recherche.
Les travaux ont pour objectif de définir une stratégie ouverte de mise en œuvre de solutions d’interopérabilité, en lien avec les grands instruments scientifiques, afin de faciliter l’analyse des données et de renforcer la reproductibilité des résultats.
Figure: Overview of Impact-HPC.
© PEPR NumPEx