

Storing massive amounts of data: better understanding for better design and optimisation
A understanding of how scientific applications read and write data is key to designing storage systems that truly meet HPC needs. Fine-grained I/O characterization helps guide both optimization strategies and the architecture of future storage infrastructures.
Data is at the heart of scientific applications, whether it be input data or processing results. For several years, data management (reading and writing, also known as I/O) has been a barrier to the large-scale deployment of these applications. In order to design more efficient storage systems capable of absorbing and optimising this I/O, it is essential to understand how applications read and write data.
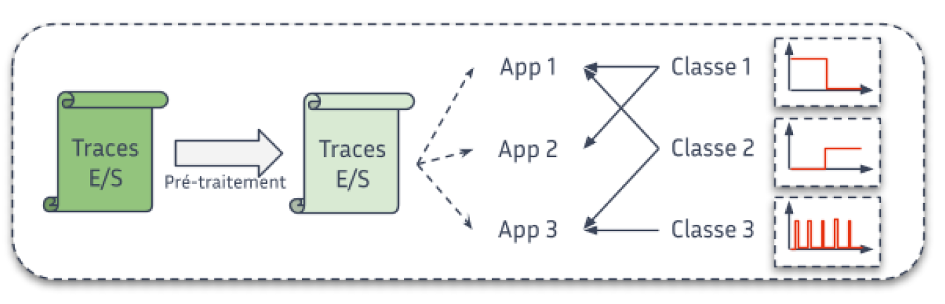
Thanks to the various tools and methods we have developed, we are able to produce a detailed characterisation of the I/O behaviour of scientific applications. For example, based on supercomputer execution data, we can show that less than a quarter of applications perform regular (periodic) accesses, or that concurrent accesses to the main storage system are less common than expected.
This type of result is decisive in several respects. For example, it allows us to propose I/O optimisation methods that respond to clearly identified application behaviours. Such characterisation is also a concrete element that influences the design choices of future storage systems, always with the aim of meeting the needs of scientific applications.
Figure: Step of data classification.
© PEPR NumPEx

A new generation of linear algebra libraries for modern supercomputers
Linear algebra libraries lie at the core of scientific computing and artificial intelligence. By rethinking their execution on hybrid CPU/GPU architectures, new task-based models enable significant gains in performance, portability, and resource utilization.
Libraries for solving or manipulating linear systems are used in many fields of numerical simulation (aeronautics, energy, materials) and artificial intelligence (training). We seek to make these libraries as fast as possible on supercomputers combining traditional processors and graphics accelerators (GPUs). To do this, we use asynchronous task-based execution models that maximise the utilisation of computing units.
This is an active area of research, but most existing approaches face the difficult problem of dividing the work into the ‘right granularity’ for heterogeneous computing units. Over the last few months, we have developed several extensions to a task-based parallel programming model called STF (Sequential Task Flow), which allows complex algorithms to be implemented in a much more elegant, concise and portable way. By combining this model with dynamic and recursive work partitioning techniques, we significantly increase performance on supercomputers equipped with accelerators such as GPUs, in particular thanks to the ability to dynamically adapt the granularity of calculations according to the occupancy of the computing units. For example, thanks to this approach, we have achieved a 2x speedup compared to other state-of-the-art libraries (MAGMA, Parsec) on a hybrid CPU/GPU computer.
Linear algebra operations are often the most costly steps in many scientific computing, data analysis and deep learning applications. Therefore, any performance improvement in linear algebra libraries can potentially have a significant impact for many users of high-performance computing resources.
The proposed extensions to the STF model are generic and can also benefit many computational codes beyond the scope of linear algebra.
In the next period, we wish to study the application of this approach to linear algebra algorithms for sparse matrices as well as to multi-linear algebra algorithms (tensor calculations).
Adapting granularity allows smaller tasks to be assigned to CPUs, which will not occupy them for too long, thus avoiding delays for the rest of the machine, while continuing to assign large tasks to GPUs so that they remain efficient.
Figure: Adjusting the grain size allows smaller tasks to be assigned to CPUs, which will not take up too much of their time, thus avoiding delays for the rest of the machine, while continuing to assign large tasks to GPUs so that they remain efficient.
© PEPR NumPEx

From Git repository to mass run: Exa-MA industrialises the deployment of NumPEx-compliant HPC applications
By unifying workflows and automating key stages of the HPC software lifecycle, the Exa-MA framework contributes to more reliable, portable and efficient application deployment on national and EuroHPC systems.
HPC applications require reproducibility, portability and large-scale testing, but the transition from code to computer remains lengthy and heterogeneous depending on the site. The objective is to unify the Exa-MA application framework and automate builds, tests and deployments in accordance with NumPEx guidelines.
An Exa-MA application framework has been set up, integrating the management of templates, metadata and verification and validation (V&V) procedures. At the same time, a complete HPC CI/CD chain has been deployed, combining Spack, Apptainer/Singularity and automated submission via ReFrame/SLURM orchestrated by GitHub Actions. This infrastructure operates seamlessly on French national computers and EuroHPC platforms, with end-to-end automation of critical steps.
In the first use cases, the time between code validation and large-scale execution has been reduced from several days to less than 24 hours, without any manual intervention on site. Performance is now monitored by non-regression tests (high/low scalability) and will soon be enhanced by profiling artefacts.
The approach deployed is revolutionising the integration of Exa-MA applications, accelerating onboarding and ensuring controlled quality through automated testing and complete traceability.
The next phase of the project involves putting Exa-MA applications online and deploying a performance dashboard.

Figure: Benchmarking website page with views by application, by machine, and by use case.
© PEPR NumPEx

From urban data to watertight multi-layer meshes, ready for city-scale energy simulation
How can we model an entire city to better understand its energy, airflow, and heat dynamics? Urban data are abundant — buildings, roads, terrain, vegetation — but often inconsistent or incomplete. A new GIS–meshing pipeline now makes it possible to automatically generate watertight, simulation-ready city models, enabling realistic energy and microclimate simulations at the urban scale.
Urban energy/wind/heat modeling requires closed and consistent geometries, while the available data (buildings, roads, terrain, hydrography, vegetation) are heterogeneous and often non-watertight. The objective is therefore to reconstruct watertight urban meshes at LoD-0/1, interoperable and enriched with physical attributes and models.
A GIS–meshing pipeline has been developed to automate the generation of closed urban models. It integrates data ingestion via Mapbox, robust geometric operations using Ktirio-Geom (based on CGAL), as well as multi-layer booleans ensuring the topological closure of the scenes. Urban areas covering several square kilometers are thus converted into consistent solid LoD-1/2 models (buildings, roads, terrain, rivers, vegetation). The model preparation time is reduced from several weeks to a few minutes, with a significant gain in numerical stability.
The outputs are interoperable with the Urban Building Model (Ktirio-UBM) and compatible with energy and CFD solvers.
This development enables rapid access to realistic urban cases, usable for energy and microclimatic simulations, while promoting the sharing of datasets within the Hidalgo² Centre of Excellence ecosystem.
The next step is to publish reference datasets — watertight models and associated scripts — on the CKAN platform (n.hidalgo2.eu). These works open the way to coupling between CFD and energy simulation, and to the creation of tools dedicated to the study and reduction of urban heat islands.

Figures: Reconstruction of the city of Grenoble within a 5 km radius, including the road network, rivers and bodies of water. Vegetation has not been included in order to reduce the size of the mesh, which here consists of approximately 6 million triangles — a figure that would at least double if vegetation were included.
© PEPR NumPEx

The 2025 annual meeting of Exa-Soft
The 2025 Exa-SofT Annual Assembly took place from 19 to 21 October, 2025, bringing together more than 60 researchers and engineers from academia and industry to discuss progress on scientific computing software, share results from work packages, and welcome the latest recruits.
Thursday, 19 October 2025
- General presentation of the project within its broader context (NumPEx)
by Raymond Namyst, professor at University of Bordeaux
and Alfredo Buttari, CNRS research scientist - Overview of each Work Package (WP)
by WP leaders
WP1 – Efficient and composable programming
models
By Marc Perache, CEA
Christian Perez, Inria
WP2 – Compilation and Automatic Code
Optimization
By Philippe Clauss, Inria
WP3 – Runtime Systems at Exascale
By Samuel Thibault, University of Bordeaux
WP4 – Numerical Libraries
By Marc Baboulin, Université Paris-Saclay
Abdou Guermouche, University of Bordeaux
WP5 – Performance analysis and
prediction
By François Trahay, Télécom SudParis
WP6 – Digital for Exascale
Energy management
By Georges Da Costa, Université de Toulouse
Amina Guermouche, Inria - Focus on 3 scientific results by recruits
by Ugo Battiston (WP1 & WP2)
Alec Sadler (WP2)
Erwan Auer (WP2)
Friday, 20 October 2025
-
Focus on 3 scientific results by recruits
by Raphaël Colin (WP2)
Thomas Morin (WP3)
Karmijn Hoogveld (WP4) -
Talk by David Goudin, Eviden
-
Introduction to our latest recruits
by Nicolas Ducarton (WP3)
Brieuc Nicolas (WP4)
Matthieu Robeyns (WP4)
Samuel Mendoza (WP4)
Jules Evans (WP6)
Assia Mighis (WP6)
3 minutes each to introduce themselves and their research -
3 presentations of mini-apps by Exa-DI
Proxy-Geos
by Henri Calandra, Total Energies
Dyablo
by Arnaud Durocher, CEA
Unstructured mesh generation for Exascale systems: a proxy application approach
by Julien Vanharen, Inria
20 minutes per mini-app: presentation + discussion on objectives, coding, status, needs, bottlenecks, and support from PC2 -
Breakout sessions for regular members / private exchanges for Board members
by Henri Calandra, Arnaud Durocher, Julien Vanharen
Technical discussions between Exa-Soft members and mini-app developers -
Board meeting feedback to Exa-Soft leaders
Session restricted to Board members, Exa-Soft leaders, and ANR
Saturday, 21 October 2025
-
Breakout sessions feedback
-
Focus on 3 scientific results by recruits
by Catherine Guelque (WP5)
Jules Risse (WP5 & WP6)
Albert d’Aviau (WP6) -
Final word: next milestones, deliverables
by Raymond Namyst, professor at University of Bordeaux
and Alfredo Buttari, CNRS research scientist
Attendees
- Emmanuel Agullo, Inria
- Erwan Auer, Inria
- Ugo Battiston, Inria
- Marc Baboulin, Université Paris-Saclay
- Vicenç Beltran Querol, BSC
- Jean-Yves Berthou, Inria
- Julien Bigot, CEA
- Jérôme Bobin, CEA
- Valérie Brenner, CEA
- Elisabeth Brunet, Telecom SudParis
- Alfredo Buttari, CNRS
- Henri Calandra, Total Energies
- Jérôme Charousset, CEA
- Philippe Clauss, Inria
- Raphaël Colin, Inria
- Albert d’Aviau de Piolant, Inria
- Georges Da Costa, Université de Toulouse
- Marco Danelutto, Université de Pise
- Stéphane de Chaisemartin, IFPEN
- Alexandre Denis, Inria
- Nicolas Ducarton, Inria
- Arnaud Durocher, CEA
- Assia Mighis, CNRS
- Bernd Mohr, Jülich
- Thomas Morin, Inria
- Jules Evans, CNRS
- Clémence Fontaine, ANR
- Nathalie Furmento, CNRS
- David Goudin, Eviden
- Catherine Guelque, Telecom SudParis
- Abdou Guermouche, Université de Bordeaux
- Amina Guermouche, Inria
- Julien Herrmann, CNRS
- Valentin Honoré, ENSIIE
- Karmijn Hoogveld, CNRS
- Félix Kpadonou, CEA
- Jerry Lacmou Zeutouo, Université de Picardie
- Sherry Li, Lawrence Berkeley National Laboratory
- Pérache Marc, CEA
- Théo Mary, CNRS
- Samuel Mendoza, Inria
- Julienne Moukalou, Inria
- Raymond Namyst, Université de Bordeaux
- Brieuc Nicolas, Inria
- Alix Peigue, INSA
- Christian Perez, Inria
- Lucas Pernollet, CEA
- Jean-Marc Pierson, IRIT
- Pierre-Etienne Polet, Inria
- Marie Reinbigler, Inria
- Vincent Reverdy, CNRS
- Jules Risse, Inria
- Matthieu Robeyns, IRIT
- Alexandre Roget, CEA
- Philippe Swartvaghe R, Inria
- Boris Teabe, ENSEEIHT
- Samuel Thibault, Université de Bordeaux
- François Trahay, Telecom SudParis
- Julien Vanharen, Inria
- Jean-Pierre Vilotte, CNRS
- Pierre Wacrenier, Inria



© PEPR NumPEx

Data logistics for radio astronomy
Mathis Certenais, PhD student at IRISA and NumPEx member, conducts his research within the ECLAT laboratory, where he develops innovative data logistics solutions for radio astronomy in the exascale era. By working closely with astrophysicists, computer scientists, and industrial partners, he designs collaborative workflows capable of meeting tomorrow’s scientific challenges, while also contributing within YoungPEx to reflections on interdisciplinarity, energy efficiency, and responsible research.
“Within YoungPEx, we are working in particular on topics such as energy footprints, how to conduct research in an environmentally responsible manner, and multidisciplinarity in the context of scientific research.”
Photo credit ECLAT Laboratory

How well do we really understand the temporal I/O behavior of HPC applications — and why does it matter?
Exa-DoST is proud to share its new publication at IPDPS 2025: A Deep Look Into the Temporal I/O Behavior of HPC Applications.
In collaboration between Inria (France), TU Darmstadt (Germany), and LNCC (Brazil), Francieli Boito, Luan Teylo, Mihail Popov, Theo Jolivel, François Tessier, Jakob Luettgau, Julien Monniot, Ahmad Tarraf, André Carneiro, and Carla Osthoff present a large-scale study of temporal I/O behavior in high-performance computing (HPC), based on more than 440,000 traces collected over 11 years from four large HPC systems.
Understanding temporal I/O behavior is critical to improving the performance of HPC applications, particularly as the gap between compute and I/O speeds continues to widen. Many existing techniques—such as burst buffer allocation, I/O scheduling, and batch job coordination—depend on assumptions about this behavior. This work examines fundamental questions about the temporality, periodicity, and concurrency of I/O behavior in real-world workloads. By analyzing traces from both system and application perspectives, we provide a detailed characterization of how HPC applications interact with the I/O subsystem over time.
Key contributions include:
- A classification of recurring temporal I/O patterns across diverse workloads.
- Insights into I/O concurrency and shared resource usage.
- Public release of the used large datasets to support further research.
Our findings offer a solid empirical foundation for future developments in behavior-aware monitoring, I/O scheduling, and performance modeling.
Read the full version on HAL.
Photo credit Francieli Boito

2025 InPEx workshop
From April 14th to 17th, 2025, the InPEx global network of experts (Europe, Japan and USA) gathered in Kanagawa, Japan. Hosted by RIKEN-CSS and Japanese universities with the support of NumPEx, the InPEx 2025 workshop was dedicated to the challenges of the post-Exascale era.
Find all NumPEx contributions below:
- Introduction, with Jean-Yves Berthou, Inria director of NumPEx and representative for Europe
-
AI and HPC: Sharing AI-centric benchmarks of hybrid workflows
Co-chaired by Jean-Pierre Vilotte (CNRS) -
Software Production and Management
Co-chaired by Julien Bigot (CEA) -
AI and HPC: Generative AI for Science
Co-chaired by Alfredo Buttari (IRIT) and Thomas Moreau (Inria) -
Digital Continuum and Data Management
Co-chaired by Gabriel Antoniu (Inria)
If you want to know more, all presentations are available on InPEx website.


Photo credit: Corentin Lefevre/Neovia Innovation/Inria

NumPEx holds its first General Assembly
Bringing together 130 researchers, engineers, and partners at Inria Saclay, the 2025 NumPEx General Assembly was a key step for the future of NumPEx.
Over two days, participants engaged in discussions, workshops, and guest talks to explore the challenges of integrating Exascale computing into a broader digital continuum. The first day was marked by the live announcement that France had been selected to host one of the European AI Factories.
This General Assembly was also the perfect occasion to introduce YoungPEx to the entire PEPR community through a presentation and one of its first workshop. YoungPEx is a new initiative aimed at fostering collaboration among young researchers, including PhD students, post-docs, engineers, and volunteer permanent researchers. It will serve as a dynamic platform for networking, knowledge exchange, and interdisciplinary collaboration across the HPC and AI communities.
We were also pleased to welcome the TRACCS and Cloud research programs, which presented both ongoing and potential collaborations with NumPEx.
With this first General Assembly, NumPEx strengthens its community and continues its paths to Exascale and beyond.





© PEPR NumPEx

The 2025 annual meeting of Exa-MA
The General Assembly of the Exa-MA project took place at the University of Strasbourg on January 14-15, 2025. This two-day event was an opportunity to share the latest advancements of the project, strengthen collaborations between Work Packages (WPs), and discuss the next steps.
Exa-MA aims to revolutionize methods and algorithms for exascale scaling: discretization, resolution, learning and order reduction, inverse problem, optimization and uncertainties. We are contributing to the software stack of future European computers.
The General Assembly gathered 83 participants, including members of the Scientific Board, external partners, and young recruits, with 15 joining online. The event featured plenary sessions, thematic workshops, and strategic discussions focused on intra- and inter-project synergies, particularly with Exa-Soft and Exa-DI. Key topics included AI, accelerators, software sustainability, and external collaborations. Strengthening ties with academic and industrial partners was also a major focus, reinforcing Exa-MA’s role in the broader exascale computing ecosystem.
Tuesday, 14 January 2025
- Welcome and General Presentations
by Hélène Barucq, Inria research scientist
and Christophe Prud’homme, professor at Université de Strasbourg - Highlighting the New Recruits
- Hung Truong, Inria postdoctoral researcher
- Céline Van Landeghem, phD student at Université de Strasbourg
- Thomas Saigre, Université de Strasbourg researcher
- Christos Giorgadis, Inria postdoctoral researcher
- Daria Hrebenshchykova, phD student at Université Côte d’Azur
- Mahamat Nassouradine, CEA phD student
- Transverse working group on AI
by Emmanuel Franck, Inria research scientist - Highlighting the New Recruits
- Antoine Simon, CEA research engineer
- Sébastien Dubois, CEA research engineer
- Alexandre Hoffmann, Inria phD student
- General workshop on interactions within the project
by Mark Asch, professor at Université de Picardie
Luc Giraud, Inria research scientist
Jean-Pierre Vilotte, CNRS research scientist - Highlighting the New Recruits
- Alexandre Pugin, Inria phD student
- Hélène Hénon, phD student at Université Grenoble Alpes
- Hassan Ballout, phD student at Université de Strasbourg
- Presentation of the NumPEx transverse working group on accelerators (GPUs)
by Philippe Helluy, professor at Université de Strasbourg - Highlighting the New Recruits
- Pierre Dubois, CEA phD student
- Amaury Bélières, pHD student at Université de Strasbourg
- Private meeting of the scientific board
Wenesday, 15 January 2025
- General workshop on interactions with external partners
by Hélène Barucq and Christophe Prud’homme - Workshop on WP1 and WP3 : discretization and solvers
by Isabelle Ramière, CEA research scientist
Pierre Alliez, Inria research scientist,
Hélène Barucq and Vincent Faucher, CEA research scientist - Workshop on WP2 and WP5 : optimization and AI
by El Ghazali Talbi, professor at Université de Lille
Stéphane Lanteri, Inria research scientist
and Emmanuel Franck - Workshop on WP4 and WP6 : uncertainty quantification + inverse problems & data assimilation
Josselin Garnier, professor at École polytechnique
Clément Gauchy, CEA research staff member
Arthur Vidard, Inria research scientist
Hélène Barucq and Florian Faucher, Inria research scientist - Feedback on workshop 1
by Isabelle Ramière, Vincent Faucher and Pierre Alliez - Feedback on workshop 2
by El Ghazali Talbi - Feedback on workshop 3
by Josselin Garnier and Arthur Vidard - Conclusion
by Christophe Prud’homme - Informal exchanges
Attendees
- Pierre Alliez, Inria
- Ani Anciaux Sedrakian, IFPEN (Online)
- Mark Asch, Université de Picardie
- Hassan Ballout, Université de Strasbourg
- Helene Barucq, Inria
- Amaury Bélières–Frendo, Université de Strasbourg
- Anne Benoit, ENS
- Jerome Bobin, CEA
- Matthieu Boileau, Université de Strasbourg
- Jérôme Bonelle, EDF
- Jed Brown, University of Colorado (Online)
- Ansar Calloo, CEA
- Vincent Chabannes, Université de Strasbourg
- Xinye Chen, Sorbonne Université (Online)
- Aurelien Citrain, Inria
- Javier Andrés Cladellas Herodier, Université de Strasbourg
- Susanne Claus, ONERA
- Raphaël Côte, Université de Strasbourg
- Clémentine Courtès, Université de Strasbourg
- Grégoire Danoy, Université de Luxembourg
- Etienne Decossin, EDF
- Romain Denefle, EDF
- Pierre Dubois, CEA
- Sébastien Dubois, École Polytechnique
- Talbi El-ghazali, Université de Lille
- Vincent Faucher, CEA
- Florian Faucher, Inria
- Emmanuel Franck, Inria
- Josselin Garnier, École Polytechnique
- Clément Gauchy, CEA
- Christos Georgiadis, Inria
- Christophe Geuzaine, Université de Liège (Online)
- Mathieu Goron, CEA (Online)
- Loic Gouarin, École Polytechnique
- Denis Gueyffier, ONERA (Online)
- Philippe Helluy, Université de Strasbourg
- Hélène Hénon, Inria
- Jan Hesthaven, Karlsruhe Institute of Technology (Online)
- Alexandre Hoffmann, École Polytechnique
- Daria Hrebenshchykova, Inria
- Bertrand Iooss, EDF
- Fabienne Jézéquel, Université Paris-Panthéon-Assas (Online)
- Pierre Jolivet, CNRS (Online)
- Baptiste Kerleguer, CEA
- Mickael Krajecki, Université de Reims
- Catherine Lambert, CERFACS
- Pierre Ledac, CEA
- Patrick Lemoine, Université de Strasbourg
- Sebastien Loriot, Geometry Factory
- Giraud Luc, Inria
- Nassouradine Mahamat Hamdan, CEA
- Bahia Maoili, ANR (Online)
- Marc Massot, École Polytechnique
- Pierre Matalon, École Polytechnique
- Loïs McInnes, Argonne National Laboratory (Online)
- Katherine Mer-Nkonga, CEA (Online)
- Victor Michel-Dansac, Inria
- Axel Modave, ENSTA (Online)
- Vincent Mouysset, ONERA
- Frédéric Nataf, Sorbonne Université
- Laurent Navoret, Université de Strasbourg
- Lars Nerger, Alfred Wegener Institute
- Augustin Parret-Fréaud, Safran
- Lucas Pernollet, CEA
- Raphaël Prat, CEA
- Clémentine Prieur, Université de Grenoble (Online)
- Christophe Prud’homme, Université de Strasbourg
- Alexandre Pugin, Inria
- Isabelle Ramiere, CEA
- Thomas Saigre, Université de Strasbourg
- Eric Savin, ONERA
- Antoine Simon, École Polytechnique
- Bruno Sudret, ETH Zürich
- Nicolas Tardieu, EDF
- Isabelle Terrasse, Airbus
- Sébastien Tordeux, Inria
- Pierre-Henri Tournier, Sorbonne Université
- Christophe Trophime, CNRS
- Hung Truong, Université de Strasbourg
- Céline Van Landeghem, Université de Strasbourg
- Arthur Vidard, Inria
- Jean-Pierre Vilotte, CNRS
- Raphael Zanella, Sorbonne Université (Online)



© PEPR NumPEx