

Exa-DoST
Exa-DoST : Logiciels et outils orientés données pour l'Exascale
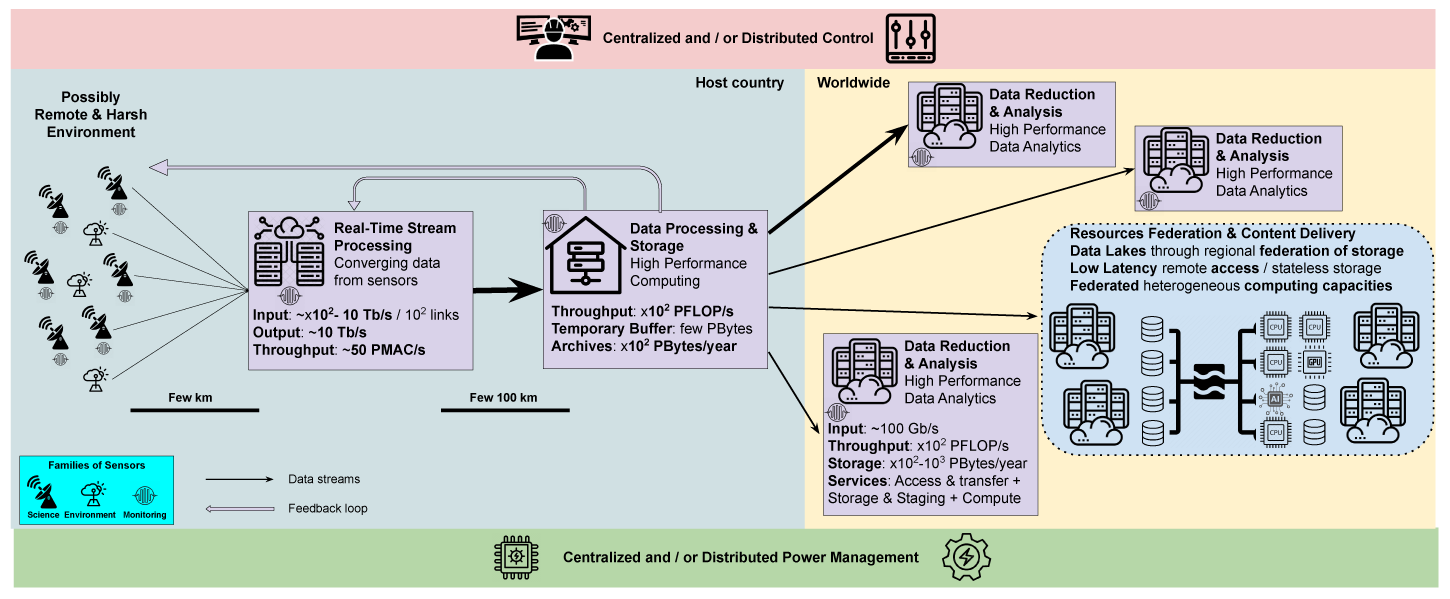
L’avènement des futurs supercalculateurs Exascale soulève de multiples défis liés aux données.
Pour permettre aux applications de tirer pleinement parti des infrastructures à venir, un défi majeur concerne l’évolutivité des techniques utilisées pour le stockage, le transfert, le traitement et l’analyse des données.
D’autres défis majeurs découlent de la nécessité d’exploiter de manière adéquate les technologies émergentes pour le stockage et le traitement, ce qui conduit à des hiérarchies de stockage nouvelles et plus complexes.
Enfin, il devient désormais nécessaire de prendre en charge des flux de travail hybrides de plus en plus complexes impliquant à la fois la simulation, l’analyse et l’apprentissage, fonctionnant à des échelles extrêmes sur des supercalculateurs interconnectés à des nuages et à des systèmes en périphérie.
Le projet Exa-DoST abordera la plupart de ces défis, organisés en 3 domaines :
1. Stockage et E/S évolutifs ;
2. Traitement in situ évolutif ;
3. Analyse intelligente évolutive.
Nombre de ces défis ont déjà été identifiés, par exemple par le projet Exascale Computing aux États-Unis ou par de nombreux projets de recherche en Europe et en France.
Dans le cadre du programme NumPEx, Exa-DoST vise un niveau de maturité technologique beaucoup plus élevé que les projets nationaux précédents concernant la pile logicielle HPC.
Il abordera les principaux défis liés aux données en proposant des solutions opérationnelles co-conçues et validées dans des applications françaises et européennes.
Cela permettra de combler le vide laissé par les projets internationaux précédents afin de s’assurer que les besoins français et européens sont pris en compte dans les feuilles de route pour la construction de la pile logicielle Exascale axée sur les données.
Logiciel
Équipes Exa-DoST déjà en place : TADaaM
Niveau de maturité: TRL 4
Évolutivité démontrée : dizaines de nœuds d’E/S
Contribution attendue des WP: WP1
AGIOS est une bibliothèque d’ordonnancement d’E/S développée par l’équipe TADaaM, conçue pour fonctionner au niveau des fichiers. Cette bibliothèque peut être facilement intégrée dans n’importe quel service d’E/S qui traite les demandes d’E/S, afin d’améliorer ces services avec des capacités d’ordonnancement. AGIOS a été évalué avec succès avec des systèmes de fichiers et met en œuvre de nombreux algorithmes d’ordonnancement. En outre, la bibliothèque est conçue pour faciliter l’ajout de nouveaux algorithmes.
Actions attendues dans le cadre du projet
Dans le contexte de NumPEx, AGIOS sera utilisé dans le développement d’un banc d’essai pour évaluer et développer de nouvelles approches de programmation d’E/S. Nous nous concentrerons principalement sur la programmation d’E/S pour les systèmes de fichiers parallèles et les tampons en rafale. Nous nous concentrerons principalement sur la planification des E/S pour les systèmes de fichiers parallèles et les mémoires tampons en rafale (burst buffers).
En outre, l’un des principaux objectifs est de faire d’AGIOS une bibliothèque compatible avec les systèmes exascales. Par conséquent, dans le cadre de NumPEx, des efforts considérables seront consacrés au développement de la bibliothèque, en mettant l’accent sur les systèmes et les charges de travail exascales.
Équipes Exa-DoST qui contribuent déjà : Kerdata
Niveau de maturité: TRL 7-8
Évolutivité démontrée : Oui
Contribution attendue des WP: WP1, WP2, WP4
Damaris est un logiciel intermédiaire HPC utilisé dans les codes de simulation basés sur MPI et développé par l’équipe KERDATA à l’Inria. Déjà démontré pour les E/S évolutives et la visualisation in situ, Damaris a été expérimenté et validé au-delà de 14 000 cœurs sur les meilleurs supercalculateurs, notamment Titan, Jaguar et Kraken, pour le traitement des données in situ/en transit. Après un projet bilatéral avec TOTAL consacré à l’utilisation de Damaris pour les codes sismiques, les travaux en cours sont maintenant consacrés à l’utilisation de Damaris sur des systèmes pré-Exascale dans le cadre de deux projets EuroHPC : ACROSS et EUPEX. Damaris sera l’une des principales bibliothèques logicielles qui sera enrichie et évaluée dans Exa-DoST pour une utilisation sur la future machine Exascale française dans le cadre des travaux planifiés dans WP1 et WP2.
Actions attendues dans le cadre du projet
Pendant la durée d’Exa-DoST, nous prévoyons d’étendre Damaris pour prendre en charge les analyses programmées et déclenchées. On parle d’analyses programmées lorsqu’un ou plusieurs programmes d’analyse sont définis, avec des calendriers individuels, pour être exécutés en utilisant un traitement asynchrone via Damaris. On parle d’analyse déclenchée lorsqu’une analyse itérative (ou programmée) détecte un processus intéressant qui déclenche alors une autre analyse plus détaillée. Le développement de ces méthodes est actuellement utilisé dans le domaine de la physique, où un code CEA appelé Coddex sera utilisé pour faciliter le développement de l’intégration, l’étalonnage et la vérification de la capacité. L’utilisation des ressources GPU par les processus Damaris est un domaine qui sera développé plus avant au cours du projet.
L’intégration des méthodes asynchrones de Damaris dans d’autres cadres in situ, tels que PDI, sera étudiée. Ceci est envisagé par le développement d’un plugin pour PDI, qui permettra à PDI de transmettre des données à Damaris. L’utilisation de nouvelles capacités MPI, telles que les sessions MPI, sera étudiée afin de voir si les processus du serveur Damaris peuvent être accédés à l’aide des nouvelles méthodes MPI. Cette méthode de lancement d’un travail sera étudiée dans sa capacité à mieux co-localiser les ressources Damaris au sein d’un nœud hétérogène et dans sa capacité à modifier de manière dynamique le nombre de ressources disponibles par le biais de Damaris.
L’utilisation d’autres cadres de communication, tels que la bibliothèque Mercury, sera testée pour voir s’ils permettent une plus grande flexibilité d’une simulation pour utiliser des méthodes in situ et aider au transfert de données et de méthodes vers des ressources informatiques distribuées.
Équipes Exa-DoST déjà en place : MdlS, DataMove
Niveau de maturité: TRL 4
Évolutivité démontrée : exécution sur la machine Adastra complète (338 nœuds × 4 AMD MI250X).
Contribution attendue des WP: WP2, WP4
Deisa est un cadre d’analyse in situ basé sur Dask. Développé au MdIS en collaboration avec l’équipe DataMove, il s’agit d’un outil python basé sur Dask. Il permet de traiter les données générées par des producteurs parallèles tels que les simulations MPI dans Dask. Deisa offre une interface python pour accéder au descripteur des données générées à l’avance et construire des graphes de tâches.
Équipes Exa-DoST déjà en place : TADaaM
Niveau de maturité: TRL 2 – Formulation du concept technologique
Évolutivité démontrée : Les tests n’ont pas encore été effectués
Contribution attendue des WP: WP1
L’I/O Performance Evaluation Suite (IOPS) est un outil développé par l’équipe TADaaM pour simplifier le processus d’exécution des tests et l’analyse des résultats dans les systèmes de stockage. Il utilise IOR, un microbenchmark pour les E/S, pour mener une série d’expériences avec différents paramètres. L’objectif de cet outil est d’automatiser le processus d’évaluation des performances des E/S, comme le décrivent Boito et al [1]. Dans cette étude, les auteurs ont exploré l’impact de plusieurs paramètres sur les performances d’E/S, tels que le nombre de nœuds, de processus et la taille des fichiers, afin de trouver une configuration permettant d’atteindre les performances maximales du système. Ensuite, ces paramètres ont été utilisés pour étudier l’impact du nombre d’OST. IOPS est conçu pour exécuter la même analyse de manière automatique et plus efficace, en réduisant le nombre d’exécutions nécessaires pour caractériser les performances d’E/S de l’ensemble du système HPC.
Actions attendues dans le cadre du projet
IOPS sera développé parallèlement au projet NUMPEX. Actuellement, l’outil dispose d’une première version qui effectue une caractérisation statique : il exécute une recherche par force brute en évaluant chaque paramètre individuellement. L’idée est de développer un outil intelligent qui prend des décisions sur l’évaluation des paramètres suivants en se basant sur les résultats des paramètres précédents. À cette fin, nous prévoyons d’utiliser l’optimisation bayésienne pour réduire le nombre d’expériences nécessaires. En outre, nous avons deux directions qui seront explorées dans le contexte de NUMPEX. Premièrement, l’outil sera développé pour être utilisé dans la caractérisation des systèmes de fichiers parallèles des systèmes exascales (exascale-compliance) ; deuxièmement, le support pour d’autres benchmarks, pas seulement pour les E/S, sera ajouté. L’idée est de disposer d’un moyen simple et automatique de caractériser les performances des plates-formes exascales.
Équipes Exa-DoST déjà en place : MIND, SODA
Niveau de maturité: TRL 7-8
Évolutivité démontrée : des centaines de nœuds
Contribution attendue des WP: WP3
Joblib est une bibliothèque développée par l’équipe MIND, dont le but est de fournir des outils simples pour exécuter des calculs embarrassants en parallèle, en passant de manière transparente entre des exécutions à un ou plusieurs nœuds. Il s’agit d’un ensemble d’outils pour fournir un pipelining léger en Python. En particulier :
- Mise en cache transparente des fonctions sur le disque et réévaluation paresseuse (mémorisation du modèle).
- Une interface simple pour un calcul parallèle embarrassant.
Joblib est optimisé pour être rapide et robuste sur les données volumineuses en particulier et dispose d’optimisations spécifiques pour les tableaux NumPy. Il est sous licence BSD.
Actions attendues dans le cadre du projet
Dans le contexte d’Exa-Dost, notre objectif est de faire de joblib un outil prêt pour Exa-Dost afin de gérer des pipelines parallèles simples pour une variété d’applications. Les actions en cours liées à NumPEx s’articulent autour de 4 axes principaux :
- L’extension des backends disponibles dans joblib pour permettre une répartition plus avancée de la charge de travail. Les liens avec l’équipe StarPU nous permettront de développer une gestion fine des flux de travail.
- Améliorer la prise en charge de la gestion des ressources et des contraintes dans joblib avec l’annotation des tâches.
- Fournir de nouveaux backends pour la mise en cache, en particulier dans le contexte de l’informatique distribuée à grande échelle. Ces backends seront basés sur des systèmes de bases de données centralisées ou des systèmes de fichiers distribués développés dans le WP3.
- Fournir une API pour un point de contrôle transparent en Python. Le point de contrôle est un élément essentiel lors du développement d’applications distribuées, que ce soit pour la tolérance aux pannes ou la sauvegarde de différents états du système pour l’inspection des résultats (performance ou analyse).
Équipes Exa-DoST déjà en place : DataMove
Niveau de maturité: Utilisé dans différents projets (nationaux, européens)
Évolutivité démontrée : 30 000 cœurs – Exécuté sur Juwels, Jean-Zay, Marenostrum et Fugaku
Contribution attendue des WP: WP2, WP3
Melissa est un logiciel développé par DataMove pour le traitement en ligne des données produites par des ensembles à grande échelle (analyse de sensibilité, assimilation de données, formation de substituts profonds).
Actions attendues dans le cadre du projet
Les travaux en cours liés à NumPex s’articulent autour de deux axes principaux :
- Transferts de données : étudiez les avantages de l’utilisation de l’ADIOS2 pour transférer des données des clients vers les serveurs (transferts de données NxM) au lieu de l’implémentation actuelle basée sur ZMQ. Les avantages sont les suivants :
- Gain de performance, car ADIOS2 devrait mieux exploiter les réseaux à haute performance que ZMQ.
- Capacités étendues pour les transferts de données NxM reposant sur les caractéristiques d’ADIOS2.
- Inférence basée sur des simulations : collaboration avec l’équipe de Statify pour déterminer si Melissa pourrait être étendu pour prendre en charge l’inférence basée sur des simulations à grande échelle (exécution d’ensemble + apprentissage en ligne à l’aide de réseaux neuronaux de diffusion réversibles).
Finalement, dans le contexte d’Exa-DoST, notre objectif est de faire de Melissa un outil prêt pour l’exascale afin de gérer des ensembles à grande échelle pour une variété d’applications.
Équipes Exa-DoST déjà en place : DSSI
Niveau de maturité: TRL 7
Évolutivité démontrée : utilisation en production sur le supercalculateur du CEA
Contribution attendue des WP: WP1, WP2, WP4
NFS-Ganesha est un serveur NFSv3/NFSv4.x/9p.2000L fonctionnant dans l’espace utilisateur et a été développé à l’origine au CEA. Des partenaires industriels, dont IBM, RedHat et Panasas, ont rejoint le projet. NFS-Ganesha est maintenant très actif dans le développement et l’évolution du projet. NFS-Ganesha fait partie de Fedora 21. NFS-Ganesha a une architecture à plusieurs niveaux. Les couches supérieures gèrent le protocole de système de fichiers distant pris en charge. Les couches les plus basses, les couches d’abstraction de système de fichiers (FSAL), fournissent un support dédié aux différents systèmes de fichiers. Chaque FSAL est fourni sous la forme d’un objet partagé, chargé dynamiquement au démarrage du serveur. Un seul serveur peut charger et utiliser plusieurs FSAL en même temps. NFS-Ganesha possède également des couches dédiées à la mise en cache agressive des métadonnées et à la gestion des états (rendant interopérables les états acquis via différents protocoles, un verrou NLMv4 peut bloquer un verrou NFSv4 ou un verrou 9p.2000L si le même objet est accédé et verrouillé). Dans le cadre de SAGE, il a été utilisé comme backend de NFS-Ganesha, pour mettre en œuvre un espace de noms POSIX à haute performance sur des objets IO-SEA. Dans ce cadre, il est utilisé comme serveur éphémère dans la pile logicielle IO-SEA.
Actions attendues dans le cadre du projet
Pendant la durée d’Exa-DoST, nous prévoyons d’utiliser NFS-Ganesha comme un « couteau suisse » pour construire des systèmes de fichiers. Le logiciel est assez polyvalent et son architecture permet de brancher facilement n’importe quel système de stockage derrière NFS-Ganesha. En particulier, NFS-Ganesha prend désormais en charge l’adressage d’objets stockés via une interface POSIX (par le biais du protocole NFS).
Équipes Exa-DoST déjà en place : MdlS, DataMove
Niveau de maturité: TRL 7
Évolutivité démontrée : plus de 300 nœuds sur Adastra
Contribution attendue des WP: WP1, WP2, WP4
L’interface de données PDI est un outil développé à MdlS qui soutient le couplage lâche des codes de simulation avec les bibliothèques. Le code de simulation est annoté de manière agnostique par rapport aux bibliothèques, puis les bibliothèques de données HPC peuvent être utilisées à partir de l’arbre de spécification sans toucher au code de simulation. Cette approche fonctionne bien pour plusieurs aspects, notamment la lecture des paramètres, l’initialisation des données, le post-traitement, le stockage des résultats sur disque, la visualisation, la tolérance aux pannes, la journalisation, l’inclusion dans le cadre du couplage des codes, l’inclusion dans le cadre d’une exécution d’ensemble, pour lesquels de nombreux modules d’extension PDI ont été mis au point. PDI est déployé en production dans plusieurs codes de simulation HPC européens à grande échelle.
Actions attendues dans le cadre du projet
Pendant la durée d’Exa-DoST, nous prévoyons de :
- Exposez les données de l’appareil directement à la PDI. PDI gérera le transfert de données entre l’hôte et l’appareil grâce à cette fonctionnalité. Nous disposons ainsi d’une méthode plus souple pour obtenir les données de l’appareil à des fins d’analyse in situ.
- Développer de nouveaux plugins dans PDI : une idée est de prendre en charge Damaris en tant que plugin PDI afin d’avoir des processus dédiés pour le mouvement des données plutôt que d’utiliser les mêmes processus que la simulation.
- Optimiser les plugins actuels pour plus de fonctionnalités. Par exemple, nous allons développer le plugin FTI pour le checkpointing.
Équipes Exa-DoST déjà en place : DSSI
Niveau de maturité: TRL5-TRL6
Évolutivité démontrée : jusqu’à des pétaoctets (il s’agit de logiciels liés au système de stockage).
Contribution attendue des WP: WP1, WP2, WP4
Phobos est un magasin d’objets open-source développé au CEA (DSSI) et axé sur le stockage à long terme et la gestion des bandes. Il est conçu comme entièrement distribué et évolutif, permettant de répartir les services sur de nombreuses machines dédiées à l’IO. Basé sur un protocole ouvert (tel que S3/Swift) et un format de stockage ouvert (tel que LTFS) pour éviter le verrouillage du fournisseur et assurer un accès à long terme aux informations stockées, sa conception permet l’utilisation de diverses bases de données, des moteurs de BD relationnels (PostGreSQL) aux moteurs NOSQL (MongoDB) et aux magasins de clés-valeurs (REDIS). Les bases de l’architecture Phobos sont des « modules / plugins backend », disponibles sous forme de bibliothèques partagées, ce qui rend Phobos capable de s’adapter à de multiples solutions matérielles.
Actions attendues dans le cadre du projet
Pendant la durée d’Exa-DoST, nous prévoyons de fournir une solution open-source pour le stockage basé sur le magasin d’objets. Le stockage d’objets est une voie importante à suivre car il offre l’évolutivité et la capacité nécessaires pour gérer le « stockage énorme » pour les systèmes Exascale (les systèmes de fichiers parallèles tels que Lustre peuvent avoir des problèmes pour s’adapter aux exigences Exascale).
Équipes Exa-DoST déjà en place : DSSI
Niveau de maturité: TRL7
Évolutivité démontrée : en production sur le supercalculateur EXA-1 du CEA
Contribution attendue des WP: WP1, WP2, WP4
RobinHood Policy Engine est un outil polyvalent développé au CEA (SISR) pour gérer le contenu de grands systèmes de fichiers. Il maintient une réplique des métadonnées du système de fichiers dans une base de données qui peut être interrogée à volonté. Il permet de planifier des actions de masse sur les entrées du système de fichiers en définissant des politiques basées sur les attributs, fournit des clones rapides améliorés par ‘find’ et ‘du’, et donne aux administrateurs une vue d’ensemble du contenu du système de fichiers grâce à son interface web et à ses outils de ligne de commande. Développé à l’origine pour le calcul intensif, il a été conçu pour effectuer toutes ses tâches en parallèle, et est donc particulièrement adapté pour fonctionner sur de grands systèmes de fichiers avec des millions d’entrées et des pétaoctets de données. Mais bien sûr, il est possible de profiter de toutes ses fonctionnalités pour gérer des systèmes de fichiers plus petits, comme le ‘/tmp’ des stations de travail. IO-SEA s’appuiera sur RobinHood en l’utilisant comme brique de base pour développer le moteur de placement vertical des données, en tirant parti de l’expérience acquise lors du développement de RobinHood ainsi que des mécanismes et algorithmes existants.
Actions attendues dans le cadre du projet
Pendant la durée d’Exa-DoST, nous prévoyons de fournir un utilitaire polyvalent lorsqu’il devient nécessaire de déclencher des actions automatisées sur des fichiers et des répertoires au sein d’un système de fichiers lorsqu’ils répondent à certaines caractéristiques identifiées. Les développements les plus récents de RobinHood ont permis d’opérer sur des objets stockés dans des magasins d’objets ainsi que sur des systèmes de fichiers.
Équipes Exa-DoST déjà en place : MIND, SODA
Niveau de maturité: TRL8
Évolutivité démontrée : des centaines de nœuds.
Contribution attendue des WP: WP3
scikit-learn est une bibliothèque de référence pour l’apprentissage automatique en Python, développée à l’Inria. Elle fournit une API simple et robuste à toutes les piles traditionnelles de ML, et en particulier :
- Des outils simples et efficaces pour l’analyse prédictive des données
- Accessible à tous et réutilisable dans différents contextes
- Construit sur NumPy, SciPy et matplotlib
- Source ouverte, utilisable commercialement – licence BSD
Actions attendues dans le cadre du projet
Pendant la durée d’Exa-DoST, nous prévoyons d’améliorer la prise en charge par scikit-learn des très grands ensembles de données et des exécutions distribuées, ainsi que son interface avec le flux de travail exascale. En particulier, nos actions viseront à :
- Amélioration de la prise en charge de l’API des tableaux avec des formats de données distribués tels que les tableaux dask, qui prennent en charge les opérations paresseuses qui peuvent être efficacement distribuées.
- Améliorer la prise en charge de l’API partial_fit, ce qui nous permettrait d’intégrer scikit-learn dans des flux de travail distribués pour analyser la sortie de grandes simulations ou d’ensembles de simulations.
Équipes Exa-DoST qui contribuent déjà : KerData
Niveau de maturité: TRL 3
Évolutivité démontrée : Capable de simuler le comportement d’un système de fichiers Lustre de 10 Po, et de rejouer ~5k travaux en ~20 minutes.
Contribution attendue des WP: WP1, WP4
Fives est un simulateur de systèmes de stockage haute performance basé sur WRENCH et SimGrid, deux cadres de simulation de pointe. En particulier, Fives peut gérer le modèle d’un système de fichiers parallèle tel que Lustre et une partition de calcul, et simuler un ensemble de travaux effectuant des entrées-sorties sur le système HPC résultant avec une grande précision. Dans Fives, un modèle de tâches est conçu pour représenter un historique de tâches et les soumettre à un planificateur de tâches (stratégie conservatrice de remplissage disponible dans WRENCH). Un modèle d’un supercalculateur existant, Theta à l’Argonne National Laboratory, et une version réimplémentée de son système de fichiers Lustre ont été développés dans ce simulateur. Sur une classe de travaux, Fives est capable de reproduire le comportement des entrées-sorties de ce système avec un bon niveau de précision par rapport aux données réelles.
Actions attendues dans le cadre du projet
Pendant la durée d’Exa-DoST, nous prévoyons d’étendre les capacités de Fives de plusieurs façons. Tout d’abord, au niveau du modèle de travail, Fives est limité à des informations très basiques sur le comportement des E/S des applications (volume total lu ou écrit, temps total d’E/S). Une évolution au sein d’Exo-DoST consistera à augmenter ce modèle afin de pouvoir décrire plus précisément les schémas d’entrées-sorties. Par conséquent, Fives sera amélioré pour prendre en compte ces nouvelles informations, afin d’améliorer la précision de notre simulateur. En ce qui concerne le modèle d’infrastructure, nous prévoyons également d’implémenter de nouveaux systèmes de stockage émergents tels que DAOS, dans le but de disposer d’abstractions suffisantes pour simuler une grande variété de systèmes de stockage à haute performance.
Consortium
Le consortium regroupe 11 équipes de recherche principales, 6 équipes de recherche associées et un partenaire industriel. Ils couvrent les deux aspects du domaine d’expertise requis pour le projet. Sur une main, l’informatique l’informatique recherche l’informatique apportent expertise sur les données recherche sur supercalculateurs de calcul intensif. D’autre part, science informatique les équipes de recherche apportent expertise sur les défis rencontrés et traités par les applications les plus avancées. les plus avancées.. Ces équipes représentent 12 des principaux établissements français impliqués dans le domaine du traitement des données à Exascale. Vous trouverez ci-dessous une brève description des équipes de base.
| Équipes de base | Institutions |
|---|---|
| DataMove | CNRS, Grenoble-INP, Inria, Université Grenoble Alpes |
| DPTA | CEA |
| IRFM | CEA |
| JLLL | CNRS, Observatoire de la Côte d’Azur, Université Côte d’Azur |
| KerData | ENS Rennes, Inria, INSA Rennes |
| LESIA | CNRS, Observatoire de Paris, Sorbonne Université, Université Paris Cité |
| LAB | CNRS, Université de Bordeaux |
| MdlS | CEA, CNRS, Université Paris-Saclay, Université de Versailles Saint-Quentin-en-Yvelines |
| MIND | CEA, Inria |
| SANL | CEA |
| SISR | CEA |
| TADaaM | Bordeaux INP, CNRS, Inria, Université de Bordeaux |
| Équipes associées | Institutions |
| CMAP | CNRS, École Polytechnique |
| IRFU | CEA |
| Laboratoire M2P2 | CNRS, Université Aix-Marseille |
| Soda | Inria |
| Stratify | CNRS, Grenoble-INP, Inria, Université Grenoble-Alpes |
| Thoth | CNRS, Grenoble-INP, Inria, Université Grenoble-Alpes |
| Entreprise DataDirect Network (DDN) |
Nos équipes
DataMove est une équipe de recherche commune entre le CNRS, Grenoble-INP, Inria et l’Université Grenoble Alpes et fait partie du Laboratoire d’informatique de Grenoble (LIG, CNRS/Université Grenoble Alpes). Créée en 2016, DataMove est aujourd’hui composée de 9 membres permanents et d’une vingtaine de doctorants, post-doctorants et ingénieurs. L’activité de recherche de l’équipe est axée sur le calcul à haute performance. Le déplacement des données sur les grands superordinateurs devient un goulot d’étranglement majeur pour les performances, et la situation ne fait qu’empirer d’une génération de superordinateurs à l’autre. L’équipe DataMove se concentre sur le calcul à grande échelle tenant compte des données et étudie des approches visant à réduire les mouvements de données sur les machines HPC à grande échelle dans deux directions de recherche principales : les algorithmes de programmation tenant compte des données pour les systèmes de gestion des tâches et le traitement des données in situ à grande échelle.
Le DPTA CEA/DAM est reconnu dans la communauté HPC pour la réalisation de codes de simulation multi-physique massivement parallèles. L’équipe du Département de Physique Théorique et Appliquée (DPTA) du DIF, dirigée par Laurent Colombet, a développé en collaboration avec Bruno Raffin (directeur de recherche à l’Inria et membre de DataMove) une composante in situ performante d’un code de simulation appelé ExaStamp, qui servira de point de départ pour les contributions au projet Exa-DoST dédié au traitement in situ.
L’Institut de recherche sur la fusion magnétique est le principal laboratoire de recherche sur la fusion magnétique en France. Depuis plus de 50 ans, il mène des recherches expérimentales et théoriques sur la fusion magnétique thermonucléaire. L’équipe de l’IRFM apporte son expertise HPC au projet à travers le code gyrocinétique 5D GYSELA qu’elle développe depuis 20 ans à travers des collaborations nationales et internationales avec une forte interaction entre physiciens, mathématiciens et informaticiens. Avec une consommation annuelle de 150 millions d’heures, l’équipe fait déjà un usage intensif des ressources petascales nationales et européennes disponibles. En raison de la physique multi-échelle en jeu et de la durée des décharges, on sait déjà que les simulations du cœur d’ITER nécessiteront des capacités HPC exascales. GYSELA servira à construire des illustrateurs pertinents pour Exa-DoST, afin de démontrer les avantages des contributions d’Exa-DoST (c’est-à-dire comment les bibliothèques améliorées, optimisées et intégrées dans Exa-DoST profiteront aux scénarios d’application basés sur GYSELA).
Le Laboratoire JL Lagrange dirige la contribution française au projet d’observatoire global SKA1, contribue à l’acquisition de ses deux supercalculateurs (SDP) et à la mise en place des Centres de Données Régionaux (SRC) du SKA. Le JLLL fait partie de l’Observatoire de la Côte d’Azur (OCA, CNRS/Université Côte d’Azur), un centre de recherche internationalement reconnu en sciences de la Terre et en astronomie. Avec un effectif de 450 personnes, l’OCA est l’un des 25 observatoires astronomiques français chargés de la collecte continue et systématique de données d’observation sur la Terre et l’Univers. Son rôle est d’explorer, de comprendre et de transférer les connaissances sur les sciences de la Terre et l’astronomie, que ce soit en astrophysique, en géosciences ou dans des sciences connexes telles que la mécanique, le traitement du signal ou l’optique. L’une des principales contributions de l’OCA au SKA se fait par l’intermédiaire de l’équipe SCOOP Agile SAFe, qui travaille sur la conception conjointe du matériel et du logiciel pour les deux superordinateurs du SKA.
KerData est une équipe commune du Centre Inria de l’Université de Rennes et du Laboratoire de recherche et d’innovation en sciences et technologies du numérique (IRISA, CNRS/Université de Rennes 1). Ses recherches portent sur la conception d’architectures et de systèmes innovants pour l’entrée/sortie, le stockage et le traitement des données sur des systèmes à échelle extrême : supercalculateurs à haute performance (pré)Exascale, infrastructures basées sur le cloud et à la périphérie. En particulier, elle aborde les exigences liées aux données des nouvelles applications complexes qui combinent la simulation, l’analyse et l’apprentissage et nécessitent des infrastructures d’exécution hybrides (supercalculateurs, nuages, périphérie).
Le Laboratoire d’Études Spatiales en Astrophysique est fortement impliqué dans la radioastronomie basse fréquence avec des responsabilités importantes dans le SKA et son précurseur NeNuFar, ainsi qu’une longue histoire d’utilisation des principales installations de radioastronomie telles que LOFAR et MeerKAT. Le LESIA fait partie de l’Observatoire de Paris (OBS.PARIS, CNRS/Université de Paris-PSL), un centre national de recherche en astronomie et astrophysique qui emploie environ 1000 personnes (750 sur des postes permanents) et est le plus grand centre d’astronomie en France. Au-delà de leur expertise unique en radio-astronomie, les équipes d’OBS.PARIS apportent de fortes compétences dans la conception et la construction d’instruments géants, y compris les capacités HPC / HPDA associées, dédiées au traitement et à la réduction des données astronomiques.
Le Laboratoire d’astrophysique de Bordeaux mène des activités de recherche et développement pour le SKA depuis 2015 afin de produire des détecteurs pour la bande 5 du réseau SKA-MID. La démonstration d’un prototype sur site est prévue en Afrique du Sud vers la mi-2024. Il s’agit actuellement de la contribution centrale et unique de la France au matériel/firmware de l’antenne/récepteur. En outre, le LAB souhaite renforcer sa contribution au SKA par le biais d’activités pertinentes pour le SKA-SDP. D’une manière générale, les scientifiques et les ingénieurs du LAB travaillent ensemble sur la science de la radio-astronomie, les logiciels et les instruments majeurs depuis plusieurs décennies (ALMA, NOEMA, SKA…), produisant des découvertes scientifiques de pointe en astrochimie, formation stellaire et planétaire, et l’étude des planètes géantes du système solaire. »
La Maison de la Simulation est un laboratoire commun au CEA, au CNRS, à l’Université Paris-Saclay et à l’Université Versailles Saint-Quentin. Elle est spécialisée dans l’informatique pour le calcul haute performance et les simulations numériques en lien étroit avec les applications physiques. Les principaux thèmes de recherche de MdlS sont le génie logiciel parallèle, les modèles de programmation, la visualisation scientifique, l’intelligence artificielle et l’informatique quantique.
MIND est une équipe Inria qui mène des recherches à l’intersection des statistiques, de l’apprentissage automatique et du traitement du signal, avec l’ambition d’influencer la recherche en neurosciences et en neuroimagerie. De plus, MIND est soutenu par le CEA et affilié à NeuroSpin, la plus grande installation de neuroimagerie en France dédiée aux champs magnétiques ultra-hauts. L’équipe MIND est une spin-off de l’équipe Parietal, située à l’Inria Saclay et au CEA Saclay.
SANL est une équipe du département informatique (DSSI) du CEA, dirigée par Marc Pérache, directeur de recherche au CEA, qui développe des outils permettant aux codes de simulation de gérer les sorties inter-codes et de post-traitement sur les supercalculateurs du CEA. Cette équipe est impliquée dans l’IO pour les codes de calcul scientifique à travers le projet Hercule. Hercule est une couche d’entrées-sorties optimisée pour traiter une grande quantité de données à l’échelle lors de grandes exécutions. Hercule gère la sémantique des données pour faire face au faible couplage du code à travers le système de fichiers (inter-code). Nous avons également étudié l’analyse in situ grâce au projet de recherche PaDaWAn.
L’équipe SISR du CEA est chargée de toutes les activités de gestion des données au sein des énormes centres de calcul intensif hébergés et gérés par le CEA/DIF. Ces activités sont très variées : conception et acquisition de nouveaux systèmes de stockage de masse, installation et maintien en conditions opérationnelles. Au-delà des tâches d’administration de systèmes, l’équipe SISR développe un large cadre de logiciels libres, fournis en tant que logiciels libres et dédiés à la gestion de données et au stockage de masse. Fortement impliqué dans les efforts de R&D, le SISR est un acteur majeur de la collaboration technique et scientifique entre le CEA et ATOS, et fait partie de nombreux projets financés par EuroHPC (en particulier le SISR pilote le projet IO-SEA).
TADaaM est une équipe de recherche commune entre l’Université de Bordeaux, l’Inria, le CNRS et Bordeaux INP, qui fait partie du Laboratoire Bordelais de Recherche en Informatique (LaBRI – CNRS/Bordeaux INP/Université de Bordeaux). Son objectif est de gérer les données à l’échelle du système en travaillant sur la façon dont les données sont accédées par le système de stockage, transférées via un réseau à haut débit ou stockées dans une mémoire (hétérogène). Pour y parvenir, TADaaM envisage de concevoir et de construire une couche de service à l’échelle du système pour la gestion des données dans les systèmes HPC, qui devrait concilier les besoins des applications et les caractéristiques du système, et combiner des informations sur les deux pour optimiser et coordonner l’exécution de toutes les applications en cours d’exécution à l’échelle du système.
Réservez la date
Événements Exa-DoST
Découvrez les prochains événements Exa-DoST : nos séminaires et conférences, ainsi que les événements de nos partenaires.
juillet, 2026
Nouvelles
Exa-DoST dernières nouvelles





L'équipe
L'équipe Exa-DoST
Découvrez les membres

Gabriel Antoniu

Julien Bigot

Francieli Zanon Boito

François Tessier

Yushan Wang

Laurent Colombet

Thomas Moreau

Bruno Raffin

Damien Gratadour

Virginie Grandgirard
Nous contacter
Rester en contact avec Exa-DoST
Laissez-nous un message, nous vous contacterons dans les plus brefs délais.