Il est essentiel de comprendre comment les applications scientifiques lisent et écrivent les données pour concevoir des systèmes de stockage qui répondent réellement aux besoins du calcul intensif. La caractérisation fine des E/S permet d’orienter les stratégies d’optimisation et l’architecture des futures infrastructures de stockage.
Les données sont au cœur des applications scientifiques, qu’il s’agisse des données en entrées ou des résultats de traitements. Depuis plusieurs années, leur gestion (lecture et écriture, aussi appelées E/S) est un frein au passage à très large échelle de ces applications. Afin de concevoir des systèmes de stockage plus performants capables d’absorber et d’optimiser ces E/S, il est indispensable de comprendre comment les applications lisent et écrivent ces données.
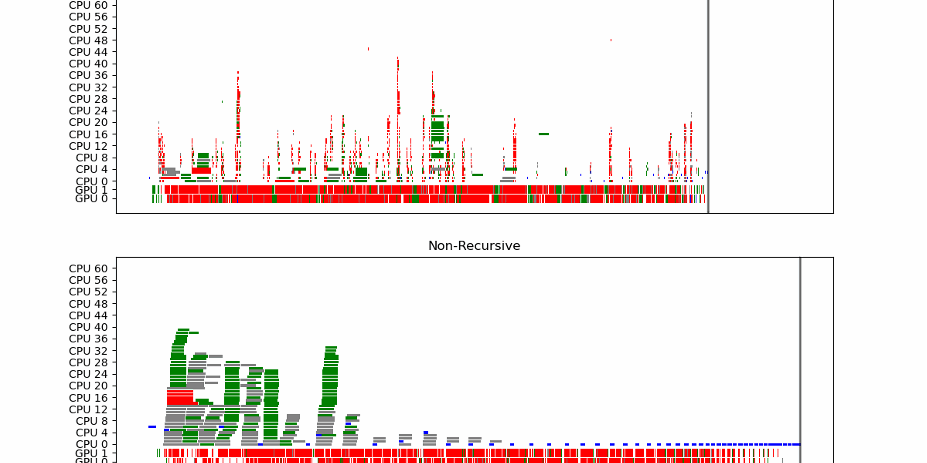
Grâce aux différents outils et méthodes que nous avons développés, nous sommes capables de produire une caractérisation fine du comportement E/S des applications scientifiques. Par exemple, à partir des données d’exécution de supercalculateurs, nous pouvons montrer que moins d’un quart des applications effectuent des accès réguliers (périodiques) ou encore que les accès concurrents sur le système de stockage principal sont moins courants qu’attendus.
Ce type de résultat est déterminant à plusieurs titres. Il permet par exemple de proposer des méthodes d’optimisation des E/S qui répondent à des comportements clairement identifiés des applications. Une telle caractérisation est aussi un élément concret pour influencer les choix de conceptions de futurs systèmes de stockage, toujours dans le but de répondre aux besoins des applications scientifiques.
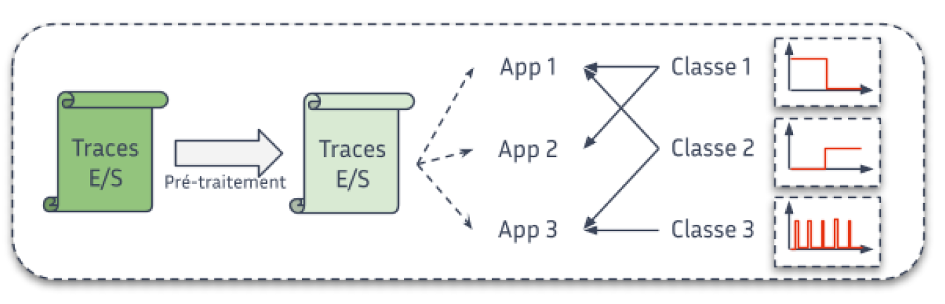
Figure : Étape de la classification des données.
PEPR NumPEx