

Strategy for the interoperability of digital scientific infrastructures
The evolution of data volumes and computing capabilities is reshaping the scientific digital landscape. To fully leverage this potential, NumPEx and its partners are developing an open interoperability strategy connecting major instruments, data centers, and computing infrastructures.
Driven by data produced by large instruments (telescopes, satellites, etc.) and artificial intelligence, the digital scientific landscape is undergoing a profound transformation, fuelled by rapid advances in computing, storage and communication capabilities. The scientific potential of this inherently multidisciplinary revolution lies in the implementation of hybrid computing and processing chains, increasingly integrating HPC infrastructures, data centres and large instruments.
Anticipating the arrival of the Alice Recoque exascale machine, NumPEx’s partners and collaborators (SKA-France, MesoCloud, PEPR NumPEx, Data Terra, Climeri, TGCC, Idris, Genci) have decided to coordinate their efforts to propose interoperability solutions that will enable the deployment of processing chains that fully exploit all research infrastructures.
The aim of the work is to define an open strategy for implementing interoperability solutions, in conjunction with large scientific instruments, in order to facilitate data analysis and enhance the reproducibility of results.
Figure: Overview of Impact-HPC.
© PEPR NumPEx

Impacts-HPC: a Python library for measuring and understanding the environmental footprint of scientific computing
The environmental footprint of scientific computing goes far beyond electricity consumption. Impacts-HPC introduces a comprehensive framework to assess the full life-cycle impacts of HPC, from equipment manufacturing to energy use, through key environmental indicators.
The environmental footprint of scientific computing is often reduced to electricity consumption during execution. However, this only reflects part of the problem. Impacts-HPC aims to go beyond this limited view by also incorporating the impact of equipment manufacturing and broadening the spectrum of indicators considered.
This tool also makes it possible to trace the stages of a computing workflow and document the sources used, thereby enhancing transparency and reproducibility. In a context where the environmental crisis is forcing us to consider climate, resources and other planetary boundaries simultaneously, such tools are becoming indispensable.
The Impacts-HPC library covers several stages of the life cycle: equipment manufacturing and use. It provides users with three essential indicators:
• Primary energy (MJ): more relevant than electricity alone, as it includes conversion losses throughout the energy chain.
• Climate impact (gCO₂eq): calculated by aggregating and converting different greenhouse gases into CO₂ equivalents.
• Resource depletion (g Sb eq): reflecting the use of non-renewable resources, in particular metallic and non-metallic minerals.
This is the first time that such a tool has been offered for direct use by scientific computing communities, with an integrated and documented approach.
This library paves the way for a more detailed assessment of the environmental impacts associated with scientific computing. The next steps include integrating it into digital twin environments, adding real-time data (energy mix, storage, transfers), and testing it on a benchmark HPC centre (IDRIS).
Figure: Overview of Impact-HPC.
© PEPR NumPEx
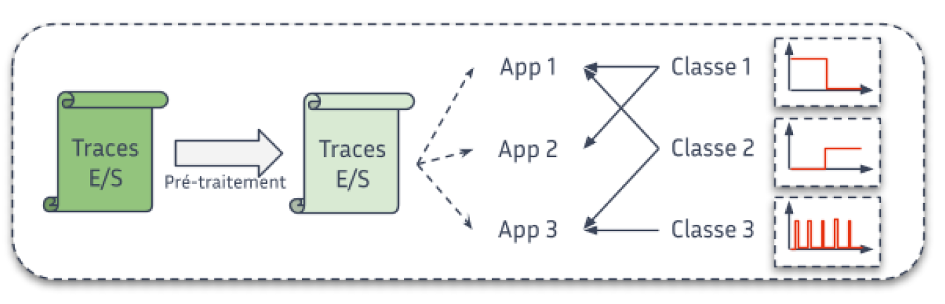
Storing massive amounts of data: better understanding for better design and optimisation
A understanding of how scientific applications read and write data is key to designing storage systems that truly meet HPC needs. Fine-grained I/O characterization helps guide both optimization strategies and the architecture of future storage infrastructures.
Data is at the heart of scientific applications, whether it be input data or processing results. For several years, data management (reading and writing, also known as I/O) has been a barrier to the large-scale deployment of these applications. In order to design more efficient storage systems capable of absorbing and optimising this I/O, it is essential to understand how applications read and write data.
Thanks to the various tools and methods we have developed, we are able to produce a detailed characterisation of the I/O behaviour of scientific applications. For example, based on supercomputer execution data, we can show that less than a quarter of applications perform regular (periodic) accesses, or that concurrent accesses to the main storage system are less common than expected.
This type of result is decisive in several respects. For example, it allows us to propose I/O optimisation methods that respond to clearly identified application behaviours. Such characterisation is also a concrete element that influences the design choices of future storage systems, always with the aim of meeting the needs of scientific applications.
Figure: Step of data classification.
© PEPR NumPEx